
What Is HTTP/2 Fingerprinting and How to Bypass It?
Advanced Data Extraction Specialist
In today's world, where web scraping and anti-scraping technologies are constantly evolving, traditional methods like User-Agent spoofing and JavaScript bypasses are no longer sufficient to counter increasingly sophisticated detection mechanisms. As websites migrate to the more efficient HTTP/2 protocol, HTTP/2 fingerprinting is quietly emerging as a powerful new anti-scraping tool.
In this article, you will learn:
- What HTTP/2 is and how it works
- Six different methods to bypass it
Let’s get started!
What is HTTP/2?
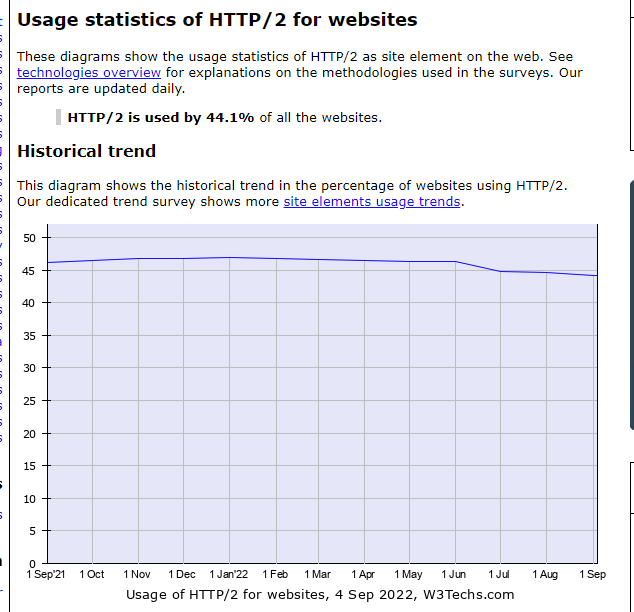
HTTP/2 is the second major version of the HTTP protocol, representing a significant upgrade over the older HTTP/1.1. Since its introduction in 2015, approximately half of all websites now use HTTP/2.
The majority of modern websites are using it! For example:
Google (including Gmail, Google Search, Google Drive, etc.)
- YouTube
- Amazon
- Netflix
You can check whether a request uses HTTP/1.1 or h2 (which stands for HTTP/2) in the browser by pressing F12 → Network.
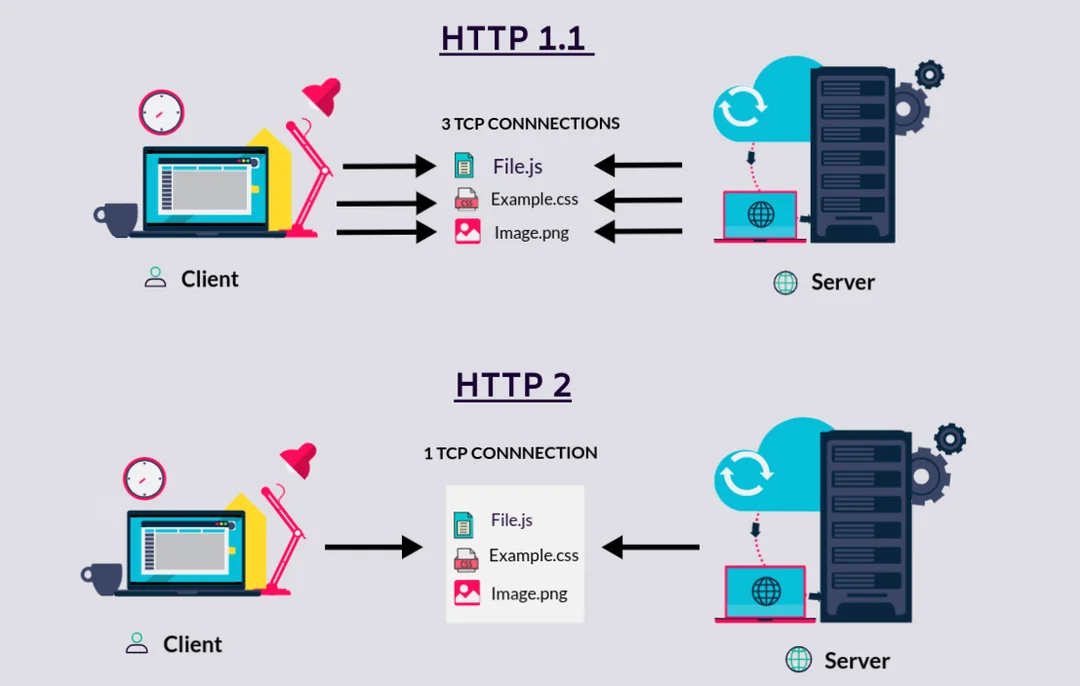
HTTP/2 is designed to improve webpage loading performance through methods like multiplexing, header compression (HPACK), and connection reuse. Unlike HTTP/1.1, which sends data serially, HTTP/2 can send multiple requests and responses in parallel over a single connection.
Core features:
- Multiplexing: multiple requests/responses share a TCP connection to improve efficiency
- Header compression: use the HPACK algorithm to reduce redundancy
- Binary protocol: more efficient transmission structure
- Priority flow control: improve resource scheduling capabilities
What is HTTP/2 Fingerprinting?
HTTP/2 fingerprinting refers to the process of identifying and categorizing clients based on behavioral differences when they use the HTTP/2 protocol. These differences often lie in the implementation details of the protocol, where different browsers, crawling libraries, and automation frameworks exhibit natural variations in their underlying behavior.
In simple terms:
Instead of looking at your User-Agent, it examines the underlying HTTP/2 behavioral characteristics when you send requests to determine who you are and whether you are a "non-human script."
As we know, HTTP/2 abandons the text format and uses a binary format for transmission, which includes many fields, such as:
| Field | Purpose |
|---|---|
| SETTINGS Frame | Represents the initial connection settings |
| PRIORITY Frame | Controls request prioritization |
| WINDOW_UPDATE | Flow control |
| Header Order | The sequence in which Headers are sent |
The values, order, and combinations of these frames/header fields vary across different clients (browsers, languages, libraries).
A fingerprinting system collects these details to build a "fingerprint database," which can be used to determine:
- Whether you're using Python's requests + httpx
- Whether you're using Playwright + Node.js
- Or if you're a "normal user" browsing with Chrome
You can check your HTTP/2 fingerprint on the BrowserLeaks HTTP/2 fingerprint test page. Below is an example:
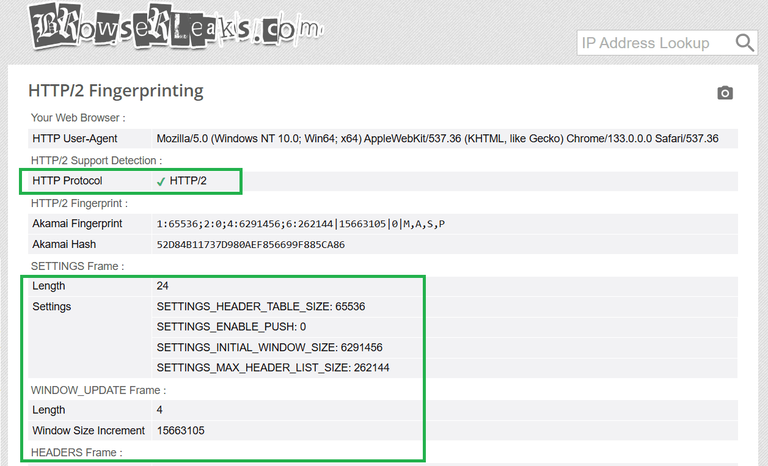
Features commonly used for identification include:
| Feature Type | Example Description |
|---|---|
| SETTINGS Frame Content | Different browsers or libraries set different parameters (e.g., max streams) |
| HEADERS Order | Order of headers like :method, :path, user-agent, accept-language, etc. |
| PRIORITY Frame Usage | Some browsers use it, while script libraries often ignore it |
| Flow Control Behavior | Whether WINDOW_UPDATE is used frequently |
| Initial Frame Combination | Some clients send multiple SETTINGS frames at the start, while others do not |
| TLS Fingerprint (JA3) | Though not part of HTTP/2 itself, it is often analyzed alongside HTTP/2 |
Why Is This Fatal for Web Crawlers?
Because HTTP/2 fingerprinting delves into the protocol layer, it is more covert and harder to forge than traditional User-Agent (UA) or JavaScript behavior detection. As we mentioned earlier, it precisely identifies whether a client is a "crawler disguised as a browser" by analyzing details such as the SETTINGS frame, frame order, window updates, and priority settings when the client initiates a connection. Most common crawling libraries (such as Python's httpx or requests, and Go's net/http) differ from real browsers in their underlying HTTP/2 implementation, making them highly susceptible to exposure.
Even worse, this type of fingerprint can identify the client before the request body is sent, meaning your crawler could be blocked by the server even before sending the actual request payload.
HTTP/2 Fingerprinting vs. Browser Fingerprinting
Although both HTTP/2 fingerprinting and browser fingerprinting are client identification techniques, they operate at different layers and use distinct identification methods. Browser fingerprinting works at the browser layer, relying on JavaScript to collect information such as browser version, plugins, fonts, screen resolution, and device type. These pieces of information can be combined into highly unique identifiers to help the server determine whether the visitor is an automated tool. However, since it relies on the front-end environment, developers can bypass detection by modifying the scripting environment or using specialized plugins.
On the other hand, HTTP/2 fingerprinting operates at the network protocol layer, identifying how the client constructs and sends HTTP/2 frames. For example, it examines low-level protocol details like the order of fields in the SETTINGS frame, initial window size, and priority settings. These characteristics are closely tied to the implementation of the operating system, TLS library, and browser engine, making them difficult to forge through simple configuration changes. Therefore, compared to browser fingerprinting, HTTP/2 fingerprinting is more concealed and harder to bypass.
For this reason, this emerging anti-crawling technique poses a more severe challenge to automation tools. The following sections will detail how to bypass HTTP/2 fingerprinting.
How to Bypass HTTP/2 Fingerprinting? (6 Practical Methods)
Since traditional spoofing techniques are easily "seen through" at the HTTP/2 level, we need more advanced strategies to make our behavior resemble that of a real browser. Below are some of the most effective methods currently available, suitable for intermediate-to-advanced crawler developers. These approaches cover everything from using headless browsers to constructing custom clients.
Method 1: Use Real Browsers to Reproduce Genuine HTTP/2 Behavior
You can use automation control tools like Puppeteer or Playwright to manipulate real Chromium browsers. The HTTP/2 protocol stack and TLS handshake behavior used by the browser inherently align with the "human user" pattern, making it harder for fingerprinting systems to detect anomalies.
A TLS handshake is a series of steps that allows both parties (usually the client and server) to authenticate each other, agree on encryption standards, and establish a secure channel for data transmission.
Implementation Recommendations:
- Run Playwright in "non-headless mode" (Headful) to simulate real user behavior;
- Enable
--enable-features=NetworkServiceInProcessto force the use of the browser's built-in HTTP/2 protocol; - Use the
puppeteer-extra-plugin-stealthplugin to hide automation traces; - Configure the browser context to match the language, timezone, and screen resolution of actual users;
- Combine with an IP proxy pool and User-Agent rotation to further avoid pattern detection.
✅ Advantages: Minimal need for low-level protocol intervention; fingerprints are naturally "human-like."
⚠️ Disadvantages: High resource consumption; crawler efficiency is limited by the browser's concurrency capacity.
Method 2: Customize an HTTP/2 Client to Simulate Real Browser Fingerprints
If you're aiming for higher concurrency performance without launching full browser instances, you’ll need to go "lower level" — manually building an HTTP/2 client that can highly mimic a real browser. This approach allows for extremely lightweight crawler requests while bypassing HTTP/2 fingerprint detection.
HTTP/2 requests initiated by browsers expose several key characteristics during the TLS handshake phase and initial frame structure, such as:
- TLS fingerprint
- ALPN protocol negotiation order
- The sequence and content of the initial SETTINGS frames
- Header order and case sensitivity (case-sensitive!)
- Use of
:authorityvshostheaders
These can all become "signal sources" for fingerprinting systems. Here’s how to address them:
Implementation Recommendations:
- Use tools like undici, http2-wrapper, hyper, or lower-level libraries like curl or nghttp2 to implement customizations.
- Simulate Chrome's HTTP/2 frame structure, including the order of SETTINGS frames, WINDOW_UPDATE behaviors, etc.
- Precisely replicate the TLS handshake process. You can use tools like mitmproxy or tls-trace to capture real browser data as a reference.
- If you’re unclear about these details, you can refer to this video for more in-depth information: https://www.youtube.com/watch?v=7BXsaU42yok.
- Use Wireshark or Chrome DevTools' chrome://net-export for packet-level comparisons.
✅ Advantages: High performance, capable of massive concurrency, no dependency on real browsers.
⚠️ Disadvantages: Extremely high development complexity; requires familiarity with protocol stacks and TLS handshake mechanisms.
Method 3: Use HTTP/2 Browser Fingerprint Proxy Services
You can also use intermediate proxy layers like TLS-Proxy to convert regular crawler requests into real browser fingerprint characteristics.
How It Works:
- The client sends requests using standard libraries (e.g.,
httpx). - The intermediate service receives the request, reconstructs HTTP/2 frames, and modifies TLS handshake information.
- The target server receives a request that mimics Chrome or Safari.
Method 4: Replay Real Browser Session Data
By exporting NetLog files from browsers or using tools like Wireshark to capture packets, you can collect and replay the HTTP/2 request process of a real browser.
Implementation Suggestions:
- Record the order of HTTP/2 frame transmissions (e.g., SETTINGS, PRIORITY, HEADERS) after launching the browser.
- Reconstruct and send the same content using tools like nghttp2 or h2.
- Ensure consistency in ALPN and JA3 fingerprints.
✅ Advantages: Almost perfectly replicates real browser requests, making it highly effective for bypassing fingerprint detection.
⚠️ Disadvantages: The packet capture and replay process is complex, suitable only for small-scale operations.
Method 5: TLS Fingerprint Synchronization (TLS Fingerprinting)
Before the HTTP/2 handshake, browsers initiate connections through the TLS protocol negotiation (ClientHello), which also generates fingerprints.
Recommended Tools:
- tls-client (Node.js)
- uTLS (Go)
- mitmproxy (Python, ideal for interception and debugging)
✅ Both TLS and ALPN must align with HTTP/2 to achieve complete simulation.
Method 6: Use Scrapeless Scraping Browser
If you're looking for a more stable, efficient, and nearly undetectable web scraping solution, Scrapeless Scraping Browser is one of the leading options available today. It operates on cloud infrastructure and leverages dynamic fingerprint obfuscation techniques to access sensitive websites without exposing the crawler's identity.
Key Features of Scrapeless:
- True Browser Environment: Simulates real user behavior at the Chrome kernel level.
- TLS Fingerprint Spoofing: Successfully bypasses most anti-crawling mechanisms (e.g., Bot, TLS, HTTP/2 fingerprinting).
- Core Technical Advantages:
- Cloud Deployment: No local resources required; easy to integrate and scale.
- Dynamic Fingerprint Obfuscation: Mimics browser environment variables and user behavior, enhancing human-like simulation.
- TLS Fingerprint Spoofing: Breaks traditional detection methods by disguising as a real browser.
- Designed for AI Agents: Supports automated proxies and Agent browser environments.
- Unlimited Parallelism: Handles large-scale scraping tasks effortlessly.
- Compatibility with Playwright/Puppeteer: Seamlessly integrates with existing automation frameworks without requiring code refactoring.
Use Cases:
- Batch data collection
- E-commerce monitoring
- Intelligence crawling
👉 Learn More and Try It Out: https://www.scrapeless.com
How to Use Scrapeless to Bypass TLS Fingerprinting
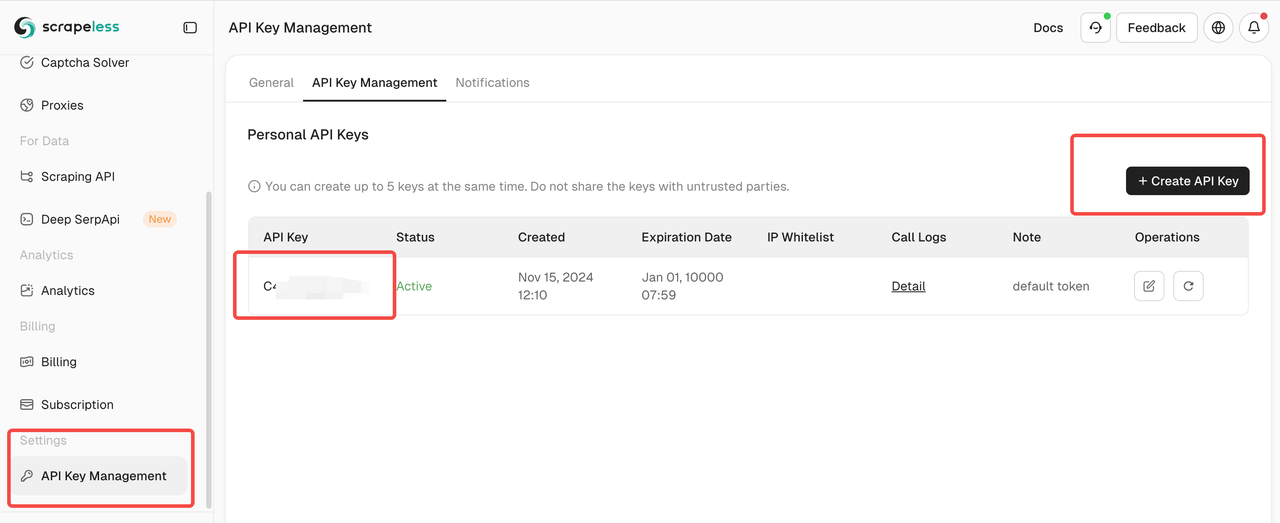
Step 1: Log in to Scrapeless and Obtain Your API Key
You can create your Scrapeless API key in the "API Key Management" section.
Step 2: Configure and Run the Scraping Browser
- Access the Scrapeless Browser Menu
- Log in to your Scrapeless account and navigate to the browser configuration menu.
- On the left, configure your API key and proxy settings.
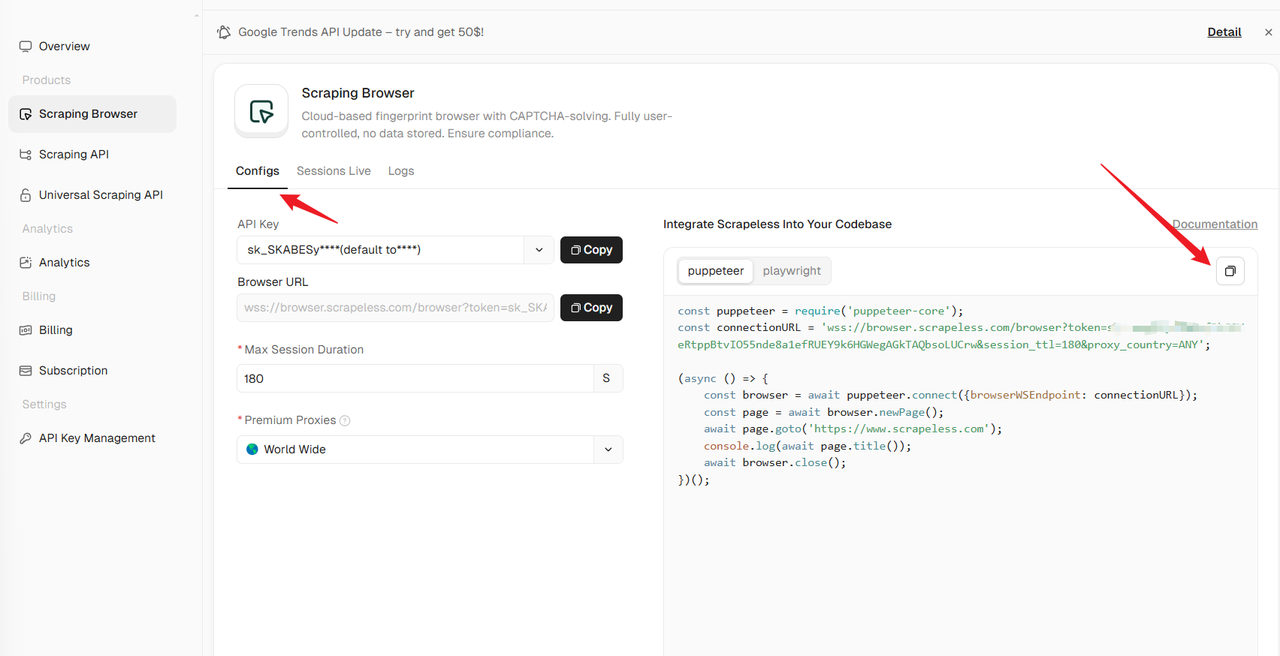
- Select a framework and copy the example code
- On the right, choose your preferred scraping framework (e.g., Playwright, Puppeteer).
- Copy the provided example code snippet. Below is an optimized example of using Playwright to bypass HTTP/2 fingerprinting:
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Then open your IDE and run the code. Here is the result:

Trend: Protocol-Level Anti-Bot Measures Will Become Mainstream
HTTP/2 fingerprinting is just the tip of the iceberg. More anti-bot mechanisms are extending to lower-level protocols, including:
- JA3 / JA4 TLS fingerprinting
- TCP Initial Sequence Number (ISN) analysis
- UDP layer behavior detection (HTTP/3)
- IP layer timing behavior statistics
In the future, anti-bot detection may identify you as a crawler even before you send your first request.
Conclusion
HTTP/2 fingerprinting has become an indispensable next-generation anti-bot technology. Relying solely on traditional methods like User-Agent spoofing or JavaScript bypasses is no longer sufficient. To stand out in modern anti-bot systems, the right strategy involves comprehensive simulation—from the protocol stack and TLS to browser behavior.
If you're looking for a high-performance, low-risk bypass solution, Scrapeless Scraping Browser offers the most human-like simulation capabilities currently available. It is the top choice for data engineers, growth hackers, and security researchers.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


