
How to Unlock imageToText CAPTCHA on Scrapeless?
Specialist in Anti-Bot Strategies
We are very excited to announce that Scrapeless Browser has officially launched the imageToText feature, which supports automatic recognition and filling of image Captcha content via the CDP!
Captcha recognition has always been a pain point in web automation, and the complexity of image Captchas has been particularly frustrating for many developers.
With the release of the imageToText feature, Scrapeless eliminates the need for additional third-party OCR services and manual intervention; everything can be automated with a single API interface for recognition and input.
Feature Highlights
- Newly Launched: The
Captcha.imageToTextCDP command. It natively supports image Captcha recognition and automatically fills in the specified input fields with the results, all within just a few seconds. - Dual Compatibility with Puppeteer and Playwright: With the Scrapeless SDK, this feature can be easily invoked in both mainstream headless browser frameworks, supporting a wider range of development scenarios.
- No Need for Image Downloads or External Service Integration: The built-in recognition engine executes directly via the CDP, making it suitable for any deployment environment.
Use Cases
- Automatically handling image Captcha when building AI agents.
- Commonly encountering product page protection during data collection on e-commerce websites.
- Image verification for login forms, registration processes, and crawler entry points.
- Enterprise-level data services require scalable solutions to bypass image verification systems.
How to Integrate the imageToText Decoding?
It is very simple to call Puppeteer; you just need to add the following code to your existing program:
JavaScript
const client = await page.createCDPSession();
await client.send("Captcha.imageToText", {
imageSelector: '.captcha__image',
inputSelector: 'input[name="captcha"]',
timeout: 30000,
})Also, we support playwright:
JavaScript
await page.goto("https://www.scrapeless.com", timeout=60000, wait_until="load")
client = await page.target.createCDPSession()
await client.send('Captcha.imageToText', {
'imageSelector': '.captcha__image',
'inputSelector': 'input[name="captcha"]',
'timeout': 30000,
})In addition, integrating the Scrapeless SDK will automatically invoke the Captcha.imageToText command, completing the image recognition and input process via the DevTools Protocol. Developers do not need any OCR configuration or third-party platform integration; it's ready to use just one click!
JavaScript
const { Puppeteer, createPuppeteerCDPSession } = require('@scrapeless-ai/sdk');
const browser = await Puppeteer.connect({
session_name: 'sdk_test',
session_ttl: 180,
proxy_country: 'US',
session_recording: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('https://www.example.com');
const cdpSession = await createPuppeteerCDPSession(page);
await cdpSession.imageToText({
imageSelector: '.captcha__image',
inputSelector: 'input[name="captcha"]',
timeout: 30000,
})Check Our Using Example!
To better understand the implementation steps of this feature, let's take the example of accessing: interception1.web.de.
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
- Using Tutorial:
- Prerequisite
Log in to the Scrapeless Dashboard and get the API Key
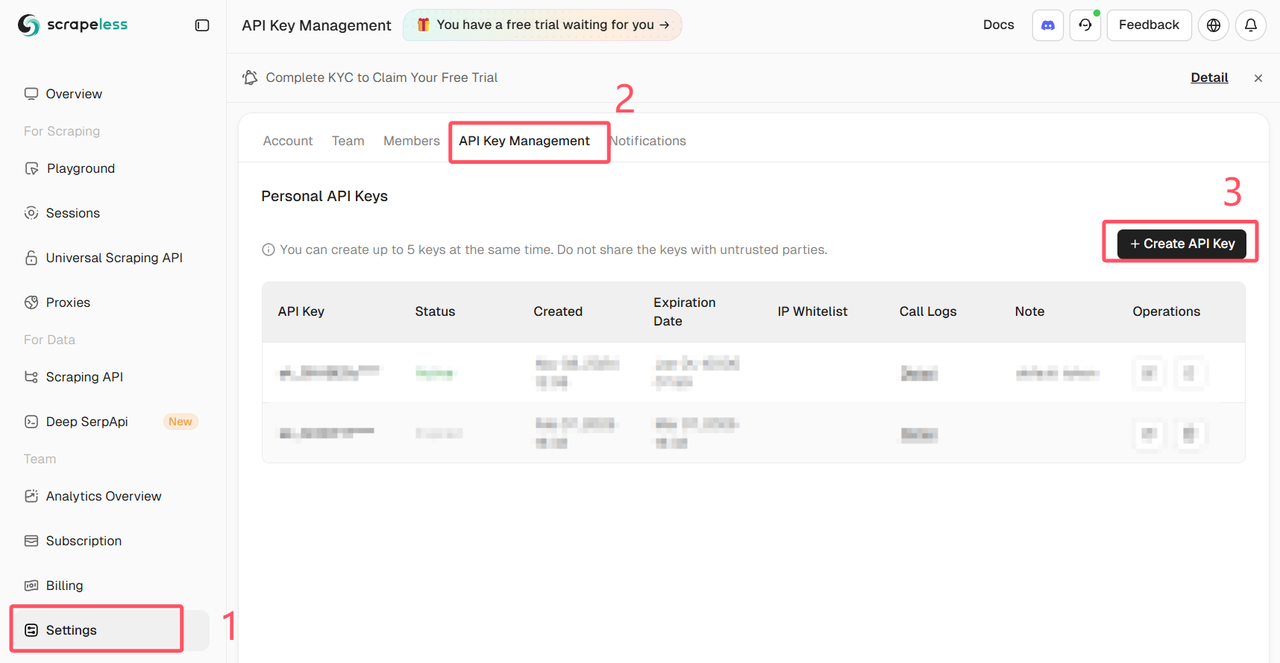
- The complete access code is as follows. Please remember to replace your API key and the target URL.
JavaScript
import puppeteer from "puppeteer-core"
const query = new URLSearchParams({
token: "YOUR_TOKEN",
proxy_country: "ANY",
session_recording: true,
session_ttl: 900,
session_name: "Default Script",
defaultViewport: null,
})
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
})
const page = await browser.newPage()
// go to your target website
await page.goto(
"https://interception1.web.de/logininterceptionfrontend/?interceptiontype=VerifyLogin&interceptiontype=VerifyLogin&service=freemail",
{
timeout: 30000,
}
);
// Creating CDP session
const client = await page.createCDPSession();
// Solve image captcha
await client.send("Captcha.imageToText", {
imageSelector: ".captcha__image", // Image captcha selector
inputSelector: 'input[name="captchaPanel:captchaImagePanel:captchaInput:topWrapper:inputWrapper:input"', // Result input selector
timeout: 30000,
});In addition, you can also bypass Captchas by integrating the Scrapeless SDK. Here is our reference code:
JavaScript
import { Puppeteer, createPuppeteerCDPSession } from '@scrapeless-ai/sdk';
async function runExample() {
console.log('Creating Puppeteer browser instance...');
const browser = await Puppeteer.connect({
session_name: 'cdp-example-session',
session_ttl: 300,
proxy_country: 'US'
});
const page = await browser.newPage();
console.log('Creating Scrapeless-enhanced CDP session...');
const cdpSession = await createPuppeteerCDPSession(page);
console.log('Navigating to login page...');
await page.goto('https://interception1.web.de/logininterceptionfrontend/?interceptiontype=VerifyLogin&interceptiontype=VerifyLogin&service=freemail');
await cdpSession.imageToText({
imageSelector: ".captcha__image", // Image captcha selector
inputSelector: 'input[name="captchaPanel:captchaImagePanel:captchaInput:topWrapper:inputWrapper:input"', // Result input selector
timeout: 30000,
});
await cdpSession.waitCaptchaDetected();
await page.screenshot({ path: 'captcha-screenshot.png' });
}
runExample();The Bottom Lines
The imageToText feature launched by Scrapeless Browser is an important upgrade to tackle the challenges of image Captcha. It integrates image recognition as a native capability of the Scrapeless SDK, providing a truly seamless experience for automation processes.
Start using the Scrapeless SDK now to take advantage of this new feature, making Captcha processing tasks more efficient and effortless!
Documentation reference: CDP API - imageToText
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


