
How to Scrape Naver Products with Scraping API?
Senior Web Scraping Engineer
With the rise of online shopping, 24% of all retail sales now come from e-commerce markets. By 2025, global e-commerce retail sales are projected to reach $7.4 trillion.
Naver, South Korea's largest search engine and tech giant, is the heart of the country's digital life. From e-commerce and digital payments to webtoons, blogs, and mobile messaging, it captures user data across more verticals than any other platform.
Naver’s architecture is designed to break predictable patterns, detect inconsistencies, and adapt faster than most systems. If your scraping strategy relies on static scripts or brute-force proxies, it’s already outdated. Successful Naver Shop data scraping isn’t just about bypassing defenses—it requires coordinating session behavior, timing logic, and aligning with platform expectations.
How can you scrape product data from Naver Shop quickly, at scale, and at minimal cost?
This guide is for business teams, data owners, and leaders facing modern Naver scraping challenges!
💼 Why Scrape Naver Data?
- Competitive Pricing Strategies: Use Naver Shopping data scraping to collect competitor pricing, enabling you to stay ahead in the market.
- Inventory Optimization: Monitor stock levels in real time to reduce shortages and improve efficiency.
- Market Trend Analysis: Identify emerging trends and consumer preferences to tailor your offerings.
- Enhanced Product Listings: Extract detailed descriptions, images, and specs to create compelling listings.
- Price Monitoring & Adjustments: Track price changes and discounts to optimize promotions.
- Competitor Analysis: Analyze rivals’ product offerings, pricing, and promotions to outperform them.
- Data-Driven Marketing: Gather consumer behavior insights for targeted campaigns.
- Improved Customer Satisfaction: Monitor reviews and ratings to refine products and boost satisfaction.
💡 What Product Data Can We Extract from Naver?
Scraping prices, stock status, descriptions, reviews, and discounts ensures comprehensive, up-to-date data. A robust Naver scraping tool can extract:
| Field | Field | Field |
|---|---|---|
| ✅ Product Name | ✅ Customer Ratings | ✅ Promotions |
| ✅ Product Features | ✅ Descriptions | ✅ Images |
| ✅ Reviews | ✅ Delivery Options | ✅ Categories |
| ✅ Subcategories | ✅ Product ID | ✅ Brand |
| ✅ Delivery Time | ✅ Return Policy | ✅ Availability |
| ✅ Price | ✅ Seller Information | ✅ Expiration Date |
| ✅ Store Location | ✅ Ingredients | ✅ Discounted Price |
| ✅ Original Price | ✅ Bundle Offers | ✅ Last Updated |
| ✅ Stock Keeping Unit (SKU) | ✅ Weight/Volume | ✅ Discount Percentage |
| ✅ Unit Price | ✅ Nutritional Information |
⚠️ What are the difficulties in scraping product information from Naver?
Before considering how to scrape data from Naver, every company should first consider the following six major challenges:
1. Lack of Stable Entry Points or Session Control
Anonymous scraping is a red flag. Naver requires consistent user behavior. Without session simulation that reflects user activity within authorized regions, your actions will seem suspicious, fragile, and quickly discarded.
2. JavaScript Rendering Challenges
JavaScript controls critical content and response times on Naver. If your extraction tool cannot accurately render JS or detect changes after loading, your data will be incomplete, outdated, or invisible. Ignoring this complexity can lead to hidden failures, distorting insights for decision-makers.
3. Session Validation, Geo-Locking, and CAPTCHA Upgrades
Every layer of automation brings risks!
- If one layer fails, your session expires.
- If two layers fail, suspicion arises.
- If three layers fail, you’ll be flagged and blocked.
Without a resilient session simulation strategy, rotating regional IPs, and automated handling of user-facing challenges (including CAPTCHA), your infrastructure becomes a house of cards.
4. Layout Changes and Interface Redesigns on Naver Shop
Naver’s changes are subtle, frequent, and unpredictable! What worked yesterday may not work today. Changes in pagination logic, tag movements, or load restructuring can severely impact your scraping tools. Your team will face constant rework, and systems must detect, respond, and self-heal—or risk resource exhaustion.
5. Rate Limiting and Blockades
When scraping large-scale data, pay attention to the number of requests and data volume within a short time. Savvy data extraction experts always focus on page operations, behavior simulation, and diversified access protocols—these are fundamental configurations for high-volume data acquisition.
6. South Korean Data Privacy and Legal Regulations
A single blind spot can cost millions! Scraping Naver data from overseas without understanding local data scraping requirements and intellectual property laws exposes your company to reputational and legal risks. It is strongly recommended to conduct thorough research before scraping.
🤔 Why Use Scrapeless to Extract Naver Product Data?
Scrapeless employs advanced web data scraping technology to ensure high-quality, precise data extraction to meet various business needs—from market analysis and competitive pricing strategies to inventory management and consumer behavior analysis. Our service provides seamless solutions for retailers, e-commerce platforms, and market analysts, helping them gain deep insights into the fast-moving consumer goods (FMCG) market.
With our Naver Scraping API, you can easily track market trends, optimize pricing strategies, and maintain a competitive edge in the rapidly evolving grocery industry. Trust us to provide actionable insights to drive your business growth and innovation.
Key Features
1️⃣ Ultra-Fast and Reliable: Quickly acquire data without compromising stability.
2️⃣ Rich Data Fields: Includes product details, seller information, pricing, ratings, and more.
3️⃣ Intelligent Proxy Rotation System: Automatically switches proxy IPs to effectively bypass IP-based access restrictions.
4️⃣ Advanced Fingerprint Technology: Dynamically simulates browser characteristics and user interaction patterns to bypass sophisticated anti-scraping mechanisms.
5️⃣ Integrated CAPTCHA Solving: Automatically handles reCAPTCHA and Cloudflare challenges, ensuring smooth data collection.
6️⃣ Automation: Fully automated scraping process with rapid response to updates.
⏯️ PLAN-A. Extract Naver product data with API
- Simply configure the Store ID and Product ID .
- The Scrapeless Naver API will extract detailed product data from Naver Shop, including pricing, seller information, reviews, and more.
- You can download and analyze the data.
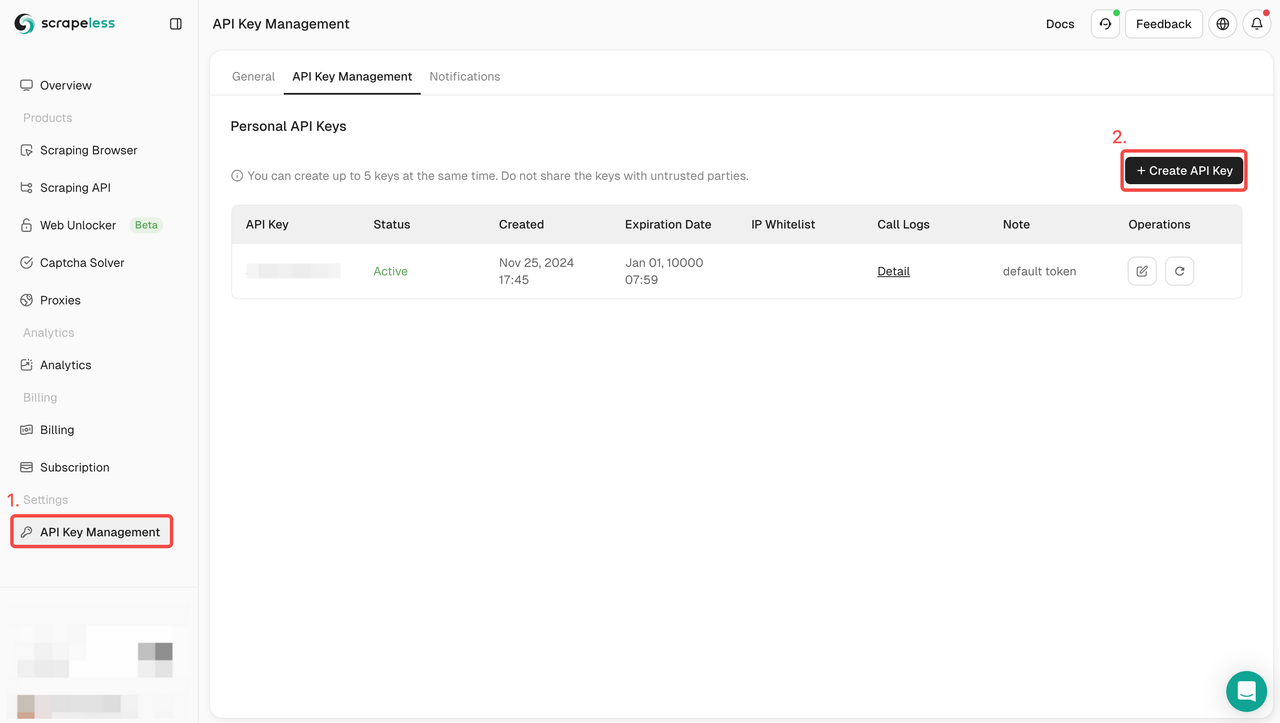
Step 1: Create your API Token
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, you can simply click on the API Key to copy it.
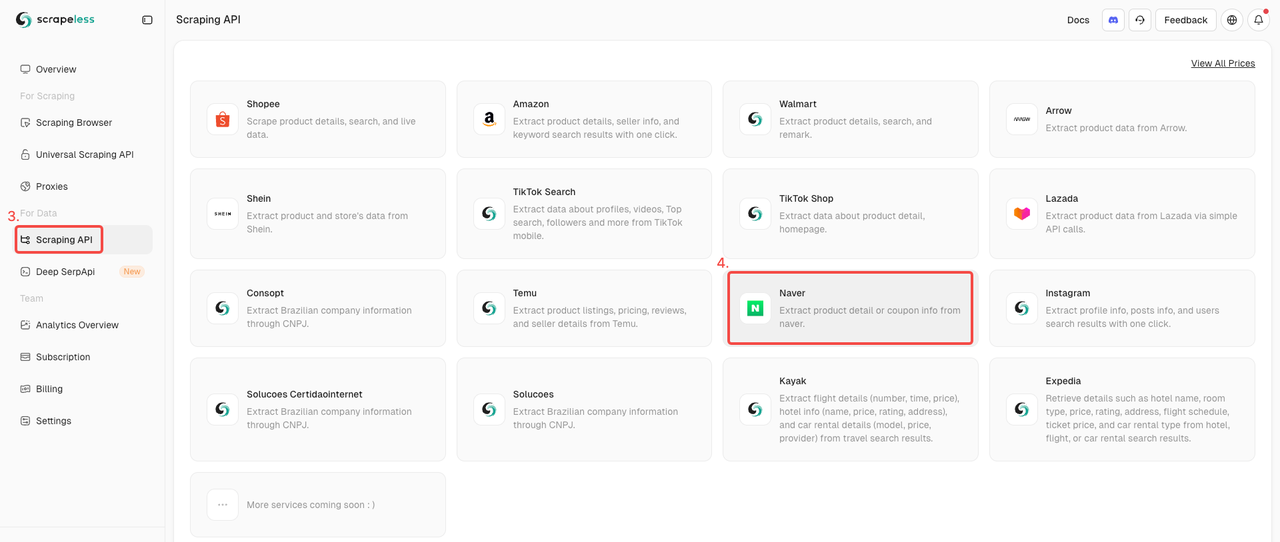
Step 2. Launch the Naver Shop API
- Find the Scraping API under the For Data collection.
- Simply click on the Naver Shop actor to get ready for scraping products data.
Step 3: Define Your Target
To scrape product data using the Naver Scraping API, you must provide two mandatory parameters: storeId and productId . The channelUid parameter is optional.
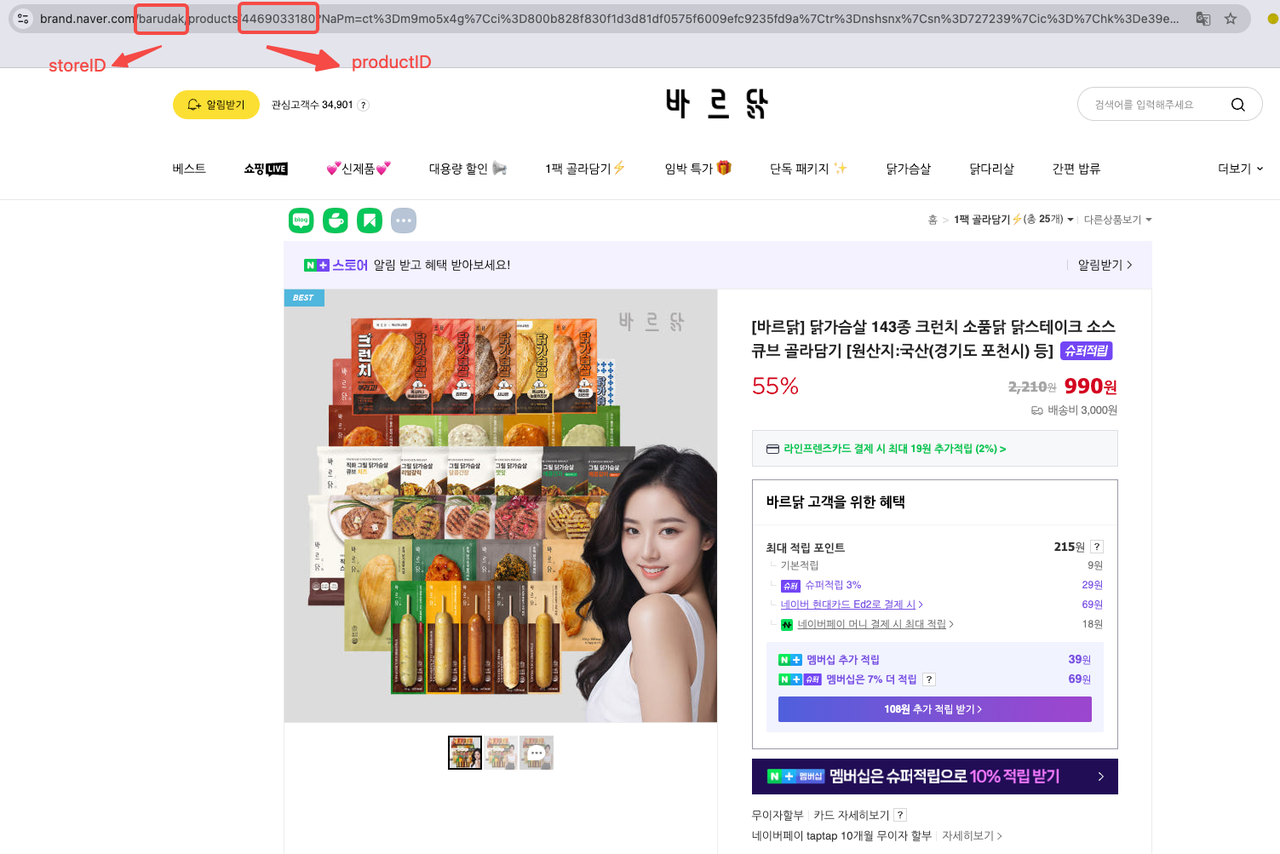
You can find the Product ID and Store ID directly in the product URL. For example:
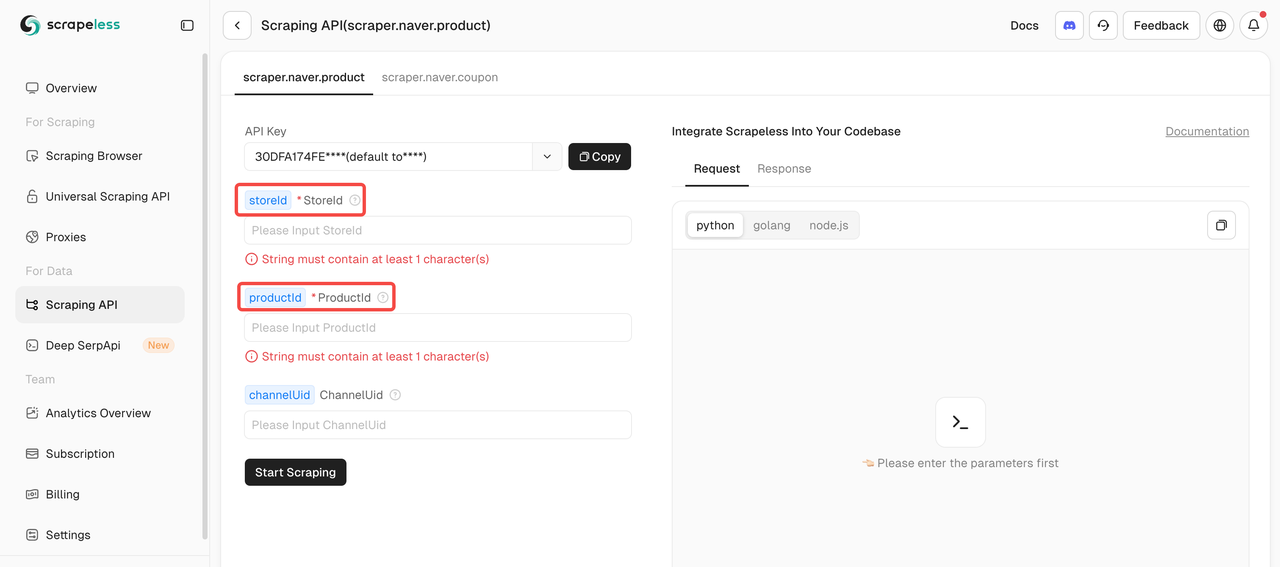
You can find the Product ID and Store ID directly in the product URL. Let's take [바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등] as an example:
- Store ID: barudak
- Product ID: 4469033180
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
Step 4: Start Scraping Naver Product Data
Once you’ve filled in the required parameters, simply click Start Scraping to obtain comprehensive product data.
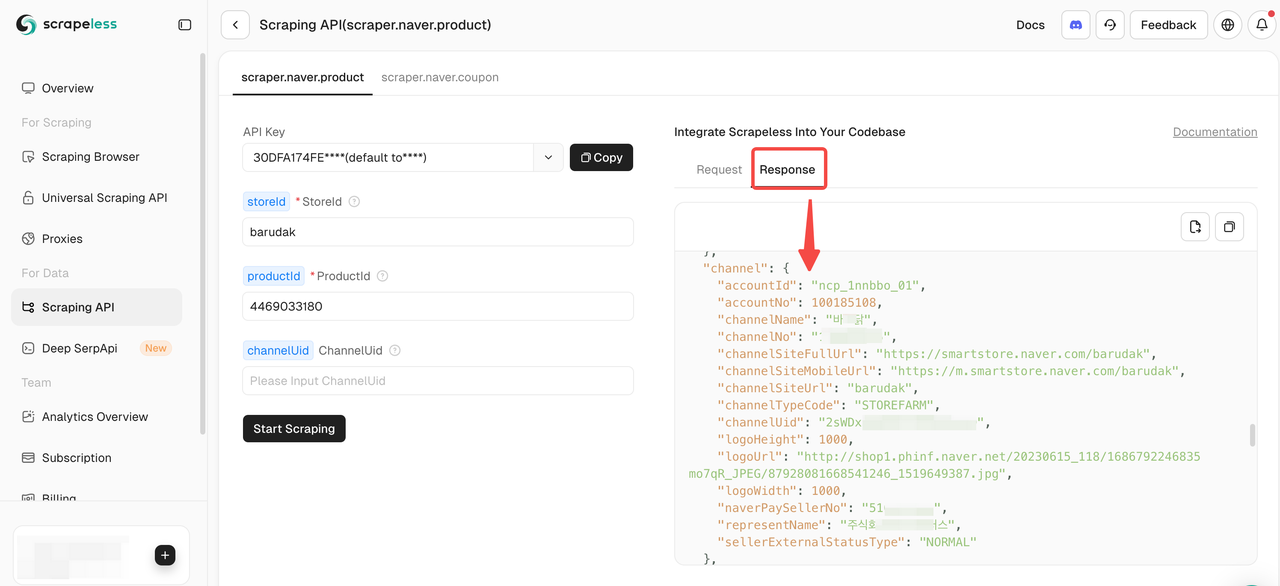
Here’s an example code snippet for extracting Naver product data. Just replace YOUR_SCRAPELESS_API_TOKEN with your actual API key:
Python
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## Optional
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()⏯️ PLAN-B. Extract Naver product data with Scraping Browser
If your team prefers programming, Scrapeless’s Scraping Browser is an excellent choice. It encapsulates all complex operations, simplifying efficient, large-scale data extraction from dynamic websites. It integrates seamlessly with popular tools like Puppeteer and Playwright.
Step 1: Integrate with Scrapeless Scraping Browser
After entering the Scraping Browser, simply fill in the configuration parameters on the left to automatically generate a scraping script.
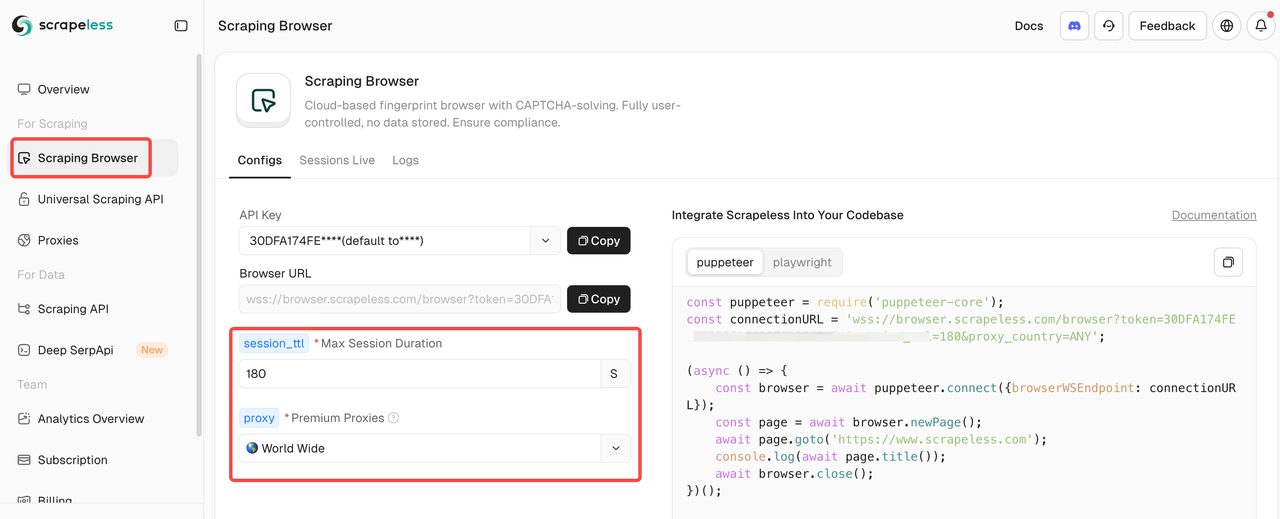
Here’s an example integration code (JavaScript recommended):
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=" YourAPIKey"&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Scrapeless automatically matches proxies for you, so no additional configuration or CAPTCHA handling is required. Combined with proxy rotation, browser fingerprint management, and robust concurrent scraping capabilities, Scrapeless ensures large-scale scraping of Naver product data without detection, efficiently bypassing IP blocks and CAPTCHA challenges.
Step 2: Set Export Format
Now, you need to filter and clean the scraped data. Consider exporting the results in CSV format for easier analysis:
JavaScript
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSV file saved: naver_product_data.csv');
await browser.close();
})();Further reading: Detailed Guide of Scrapeless Scraping Browser
Here is our scraping script, as a reference:
JavaScript
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { parse } = require('json2csv');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YourAPIKey&session_ttl=180&proxy_country=KR';
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
// Replace with the URL of the Naver product page you actually want to crawl
const url = 'https://smartstore.naver.com/barudak/products/4469033180';
await page.goto(url, { waitUntil: 'networkidle2' });
// Simple example: crawl product title, price, description, etc. (adapt according to the actual page structure)
const productData = await page.evaluate(() => {
const title = document.querySelector('h3._2Be85h')?.innerText || '';
const price = document.querySelector('span._1LY7DqCnwR')?.innerText || '';
const description = document.querySelector('div._2w4TxKo3Dx')?.innerText || '';
return {
title,
price,
description
};
});
console.log('Product data:', productData);
// Export to CSV
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSV file saved: naver_product_data.csv');
await browser.close();
})();Congratulations, you have successfully completed the entire process of crawling Naver product data!
The Bottom Lines
Scraping Naver data is a strategic investment! However, when teams use programming to scrape, they need to implement adaptive systems, coordinate session behaviors, and strictly adhere to platform regulations and South Korean data laws. Competing with Naver’s dynamic architecture means configuring proxies, CAPTCHA solvers, and simulating real user operations—all labor-intensive tasks.
In reality, we don’t need to spend much time on maintenance! To achieve this, simply leverage a robust tech stack, including browser automation tools and APIs, ensuring scalable, compliant Naver product data extraction at any scale without worrying about web blocks.
Start your free trial now! At just $3 for 1,000 requests, it’s the lowest price on the web!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


