
What Response Parameters Can You Get on Scrapeless?
Senior Web Scraping Engineer
In modern web data scraping scenarios, simply retrieving HTML pages often falls short of meeting business needs when facing sophisticated anti-scraping mechanisms. At Scrapeless, we remain committed to elevating our product capabilities from a developer's perspective.
Today, we are thrilled to announce a major update to one of Scrapeless' core services — the Universal Scraping API. Web Unlocker now supports multiple response formats! This enhancement significantly boosts API flexibility, delivering a more adaptable and efficient data scraping experience for enterprise users and developers alike.
Why Do We Make an Update?
Previously, the Universal Scraping API defaulted to returning HTML page content, which worked well for quickly accessing unencrypted pages or websites with weaker anti-scraping measures. However, as user demands for automation grew, we observed that many users still had to manually process data structures, clean content, and extract elements after obtaining the HTML—adding unnecessary development overhead. Could we streamline this process to deliver pre-processed content in one step?
Now you can!
We've revamped the response logic. By configuring the response_type parameter, developers can flexibly specify the desired data format. Whether you need raw HTML, plain text, or structured metadata, a simple parameter configuration is all it takes.
Now, Response Formats You Can Get:
Currently supported formats include but are not limited to:
- JSON output filters: Use the
outputsparameter to filter JSON-formatted data. Allowed filter types includeemail,phone_numbers,headings, and 9 others, with results returned in structured JSON. - Multiple return formats: Beyond JSON filtering, you can directly specify the response format by adding the
response_typeparameter to your request (e.g.,response_type=plaintext).
Currently supported formats include:
HTML: Extracts page content in HTML format (ideal for static pages).Plaintext: Returns scraped content as plain text, stripped of HTML tags or Markdown formatting—perfect for text processing or analysis.Markdown: Extracts page content in Markdown format (optimal for static Markdown-based pages), making it easier to read and process.PNG/JPEG: By settingresponse_type=png, captures a screenshot of the target page and returns it in PNG or JPEG format (with options for full-page screenshots).
Note: The default response_type is html.
Let's Figure out Examples
1. JSON return value filtering:
You can use the outputs parameter to filter data in JSON format. Once this parameter is set, the response type will be fixed to JSON.
The parameter accepts a list of filter names separated by commas and returns the data in a structured JSON format. Supported filter types include: phone_numbers, headings, images, audios, videos, links, menus, hashtags, emails, metadata, tables, and favicon.
The following sample code demonstrates how to get all the image information on the scrapeless site homepage:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- Results:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
]
}2. HTML
Add response_type=html to the request to return HTML formatted text content:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.example.com",
js_render: true,
response_type: "html"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.html', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.example.com",
"js_render": True,
"response_type": "html"
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.html', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- Results:
HTML
<!DOCTYPE html><html><head>
<title>Example Domain</title>
<meta charset="utf-8">
<meta http-equiv="Content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body></html>3. Plaintext
The Plain Text feature is an output option that returns the scraped content in plain text instead of HTML or Markdown. It simplifies the content extraction process and makes text processing or analysis more convenient.
The following example shows how to get the plain text content of a page.
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://apidocs.scrapeless.com/llms.txt",
js_render: true,
response_type: "plaintext",
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.txt', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://apidocs.scrapeless.com/llms.txt",
"js_render": True,
"response_type": "plaintext",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.txt', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- Results:
Plain Text
# Scrapeless API
## Docs
- Scraping Browser [CDP API](https://apidocs.scrapeless.com/doc-801748.md):
- Scraping API > shopee [Actor List](https://apidocs.scrapeless.com/doc-754333.md):
- Scraping API > amazon [API Parameters](https://apidocs.scrapeless.com/doc-857373.md):
- Scraping API > google search [API Parameters](https://apidocs.scrapeless.com/doc-800321.md):
- Scraping API > google trends [API Parameters](https://apidocs.scrapeless.com/doc-796980.md):
- Scraping API > google flights [API Parameters](https://apidocs.scrapeless.com/doc-796979.md):
- Scraping API > google flights chart [API Parameters](https://apidocs.scrapeless.com/doc-908741.md):
- Scraping API > google maps [API Parameters(Google Maps)](https://apidocs.scrapeless.com/doc-834792.md):
- Scraping API > google maps [API Parameters(Google Maps Autocomplete)](https://apidocs.scrapeless.com/doc-834799.md):
- Scraping API > google maps [API Parameters(Google Maps Contributor Reviews)](https://apidocs.scrapeless.com/doc-834806.md):
- Scraping API > google maps [API Parameters(Google Maps Directions)](https://apidocs.scrapeless.com/doc-834821.md):
- Scraping API > google maps [API Parameters(Google Maps Reviews)](https://apidocs.scrapeless.com/doc-834831.md):
- Scraping API > google scholar [API Parameters(Google Scholar)](https://apidocs.scrapeless.com/doc-842638.md):
- Scraping API > google scholar [API Parameters(Google Scholar Author)](https://apidocs.scrapeless.com/doc-842645.md):
- Scraping API > google scholar [API Parameters(Google Scholar Cite)](https://apidocs.scrapeless.com/doc-842647.md):
- Scraping API > google scholar [API Parameters(Google Scholar Profiles)](https://apidocs.scrapeless.com/doc-842649.md):
- Scraping API > google jobs [API Parameters](https://apidocs.scrapeless.com/doc-850038.md):
- Scraping API > google shopping [API Parameters](https://apidocs.scrapeless.com/doc-853695.md):
- Scraping API > google hotels [API Parameters](https://apidocs.scrapeless.com/doc-865231.md):
- Scraping API > google hotels [Supported Google Vacation Rentals Property Types](https://apidocs.scrapeless.com/doc-890578.md):
- Scraping API > google hotels [Supported Google Hotels Property Types](https://apidocs.scrapeless.com/doc-890580.md):
- Scraping API > google hotels [Supported Google Vacation Rentals Amenities](https://apidocs.scrapeless.com/doc-890623.md):
- Scraping API > google hotels [Supported Google Hotels Amenities](https://apidocs.scrapeless.com/doc-890631.md):
- Scraping API > google news [API Parameters](https://apidocs.scrapeless.com/doc-866643.md):
- Scraping API > google lens [API Parameters](https://apidocs.scrapeless.com/doc-866644.md):
- Scraping API > google finance [API Parameters](https://apidocs.scrapeless.com/doc-873763.md):
- Scraping API > google product [API Parameters](https://apidocs.scrapeless.com/doc-880407.md):
- Scraping API [google play store](https://apidocs.scrapeless.com/folder-3277506.md):
- Scraping API > google play store [API Parameters](https://apidocs.scrapeless.com/doc-882690.md):
- Scraping API > google play store [Supported Google Play Categories](https://apidocs.scrapeless.com/doc-882822.md):
- Scraping API > google ads [API Parameters](https://apidocs.scrapeless.com/doc-881439.md):
- Universal Scraping API [JS Render Docs](https://apidocs.scrapeless.com/doc-801406.md):
## API Docs
- User [Get User Info](https://apidocs.scrapeless.com/api-11949851.md): Retrieve basic information about the currently authenticated user, including their account balance and subscription plan details.
- Scraping Browser [Connect](https://apidocs.scrapeless.com/api-11949901.md):
- Scraping Browser [Running sessions](https://apidocs.scrapeless.com/api-16890953.md): Get all running sessions
- Scraping Browser [Live URL](https://apidocs.scrapeless.com/api-16891208.md): Get live url of an running session by session task id
- Scraping API > shopee [Shopee Product](https://apidocs.scrapeless.com/api-11953650.md):
- Scraping API > shopee [Shopee Search](https://apidocs.scrapeless.com/api-11954010.md):
- Scraping API > shopee [Shopee Rcmd](https://apidocs.scrapeless.com/api-11954111.md):
- Scraping API > br sites [Solucoes cnpjreva](https://apidocs.scrapeless.com/api-11954435.md): target url `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- Scraping API > br sites [Solucoes certidaointernet](https://apidocs.scrapeless.com/api-12160439.md): target url `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`
- Scraping API > br sites [Servicos receita](https://apidocs.scrapeless.com/api-11954437.md): target url `https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp`
- Scraping API > br sites [Consopt](https://apidocs.scrapeless.com/api-11954723.md): target url `https://consopt.www8.receita.fazenda.gov.br/consultaoptantes`
- Scraping API > amazon [product](https://apidocs.scrapeless.com/api-12554367.md):
- Scraping API > amazon [seller](https://apidocs.scrapeless.com/api-12554368.md):
- Scraping API > amazon [keywords](https://apidocs.scrapeless.com/api-12554373.md):
- Scraping API > google search [Google Search](https://apidocs.scrapeless.com/api-12919045.md):
- Scraping API > google search [Google Images](https://apidocs.scrapeless.com/api-16888104.md):
- Scraping API > google search [Google Local](https://apidocs.scrapeless.com/api-16890459.md):
- Scraping API > google trends [AutoComplete](https://apidocs.scrapeless.com/api-12730912.md):
- Scraping API > google trends [Interest Over Time](https://apidocs.scrapeless.com/api-12731035.md):
- Scraping API > google trends [Compared Breakdown By Region](https://apidocs.scrapeless.com/api-12731046.md):
- Scraping API > google trends [Interest By Subregion](https://apidocs.scrapeless.com/api-12731059.md):
- Scraping API > google trends [Related Queries](https://apidocs.scrapeless.com/api-12731060.md):
- Scraping API > google trends [Related Topics](https://apidocs.scrapeless.com/api-12731091.md):
- Scraping API > google trends [Trending Now](https://apidocs.scrapeless.com/api-16315096.md):
- Scraping API > google flights [Round trip](https://apidocs.scrapeless.com/api-12798120.md):
- Scraping API > google flights [One way](https://apidocs.scrapeless.com/api-12798122.md):
- Scraping API > google flights [Multi-city](https://apidocs.scrapeless.com/api-12798127.md):
- Scraping API > google flights chart [chart](https://apidocs.scrapeless.com/api-15419356.md):
- Scraping API > google maps [Google Maps](https://apidocs.scrapeless.com/api-13727737.md):
- Scraping API > google maps [Google Maps Autocomplete](https://apidocs.scrapeless.com/api-13728055.md):
- Scraping API > google maps [Google Maps Contributor Reviews](https://apidocs.scrapeless.com/api-13728193.md):
- Scraping API > google maps [Google Maps Directions](https://apidocs.scrapeless.com/api-13728584.md):
- Scraping API > google maps [Google Maps Reviews](https://apidocs.scrapeless.com/api-13728997.md):
- Scraping API > google scholar [Google Scholar](https://apidocs.scrapeless.com/api-13922772.md):
- Scraping API > google scholar [Google Scholar Author](https://apidocs.scrapeless.com/api-13923148.md):
- Scraping API > google scholar [Google Scholar Cite](https://apidocs.scrapeless.com/api-13923179.md):
- Scraping API > google scholar [Google Scholar Profiles](https://apidocs.scrapeless.com/api-13923189.md):
- Scraping API > google jobs [Google Jobs](https://apidocs.scrapeless.com/api-14029711.md):
- Scraping API > google shopping [Google Shopping](https://apidocs.scrapeless.com/api-14111890.md):
- Scraping API > google hotels [Google Hotels](https://apidocs.scrapeless.com/api-14516185.md):
- Scraping API > google news [Google News](https://apidocs.scrapeless.com/api-14581677.md):
- Scraping API > google lens [Google Lens](https://apidocs.scrapeless.com/api-14581678.md):
- Scraping API > google finance [Google Finance](https://apidocs.scrapeless.com/api-14757813.md):
- Scraping API > google finance [Google Finance Markets](https://apidocs.scrapeless.com/api-14815971.md):
- Scraping API > google product [Google Product](https://apidocs.scrapeless.com/api-14946686.md):
- Scraping API > google play store [Google Play Games](https://apidocs.scrapeless.com/api-15020703.md):
- Scraping API > google play store [Google Play Books](https://apidocs.scrapeless.com/api-15020704.md):
- Scraping API > google play store [Google Play Movies](https://apidocs.scrapeless.com/api-15020705.md):
- Scraping API > google play store [Google Play Product](https://apidocs.scrapeless.com/api-15020707.md):
- Scraping API > google play store [Google Play Apps](https://apidocs.scrapeless.com/api-15020056.md):
- Scraping API > google ads [Google Ads](https://apidocs.scrapeless.com/api-14981770.md):
- Scraping API [Scraper Request](https://apidocs.scrapeless.com/api-11949852.md):
- Scraping API [Scraper GetResult](https://apidocs.scrapeless.com/api-11949853.md):
- Universal Scraping API [JS Render](https://apidocs.scrapeless.com/api-12948840.md):
- Universal Scraping API [Web Unlocker](https://apidocs.scrapeless.com/api-11949854.md):
- Universal Scraping API [Akamaiweb Cookie](https://apidocs.scrapeless.com/api-11949855.md):
- Universal Scraping API [Akamaiweb Sensor](https://apidocs.scrapeless.com/api-11949856.md):
- Crawler > Scrape [Scrape a single URL](https://apidocs.scrapeless.com/api-17509002.md):
- Crawler > Scrape [Scrape multiple URLs](https://apidocs.scrapeless.com/api-17509003.md):
- Crawler > Scrape [Cancel a batch scrape job](https://apidocs.scrapeless.com/api-17509005.md):
- Crawler > Scrape [Get the status of a scrape](https://apidocs.scrapeless.com/api-17644667.md):
- Crawler > Scrape [Get the status of a batch scrape job](https://apidocs.scrapeless.com/api-17509004.md):
- Crawler > Scrape [Get the errors of a batch scrape job](https://apidocs.scrapeless.com/api-17509006.md):
- Crawler > Crawl [Crawl multiple URLs based on options](https://apidocs.scrapeless.com/api-17509010.md):
- Crawler > Crawl [Cancel a crawl job](https://apidocs.scrapeless.com/api-17509008.md):
- Crawler > Crawl [Get the status of a crawl job](https://apidocs.scrapeless.com/api-17509007.md):
- Crawler > Crawl [Get the errors of a crawl job](https://apidocs.scrapeless.com/api-17509009.md):
- Public [actor status ](https://apidocs.scrapeless.com/api-12408851.md):
- Public [actor status](https://apidocs.scrapeless.com/api-12409228.md): 4. Markdown
By adding response_type=markdown in the request parameters, Scrapeless Universal Scraping API will return the content of a specific page in Markdown format.
The following example shows the markdown effect of the Scraping Browser Quickstart page. We first use the page inspection to obtain the CSS selector of the table.
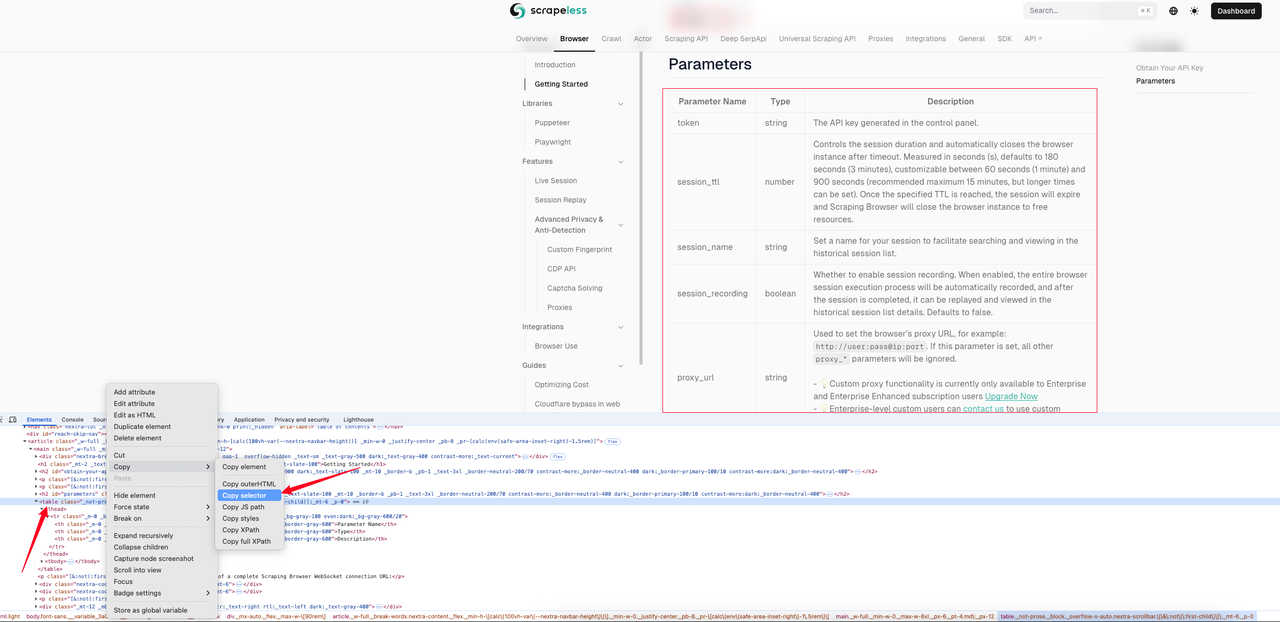
In this example, the CSS selector we get is: #__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table. The following is the complete sample code.
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // CSS selector of the page table element
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # CSS selector of the page table element
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])Display of the crawled table markdown text:
Markdown
| Parameter Name | Type | Description |
| --- | --- | --- |
| token | string | The API key generated in the control panel. |
| session_ttl | number | Controls the session duration and automatically closes the browser instance after timeout. Measured in seconds (s), defaults to 180 seconds (3 minutes), customizable between 60 seconds (1 minute) and 900 seconds (recommended maximum 15 minutes, but longer times can be set). Once the specified TTL is reached, the session will expire and Scraping Browser will close the browser instance to free resources. |
| session_name | string | Set a name for your session to facilitate searching and viewing in the historical session list. |
| session_recording | boolean | Whether to enable session recording. When enabled, the entire browser session execution process will be automatically recorded, and after the session is completed, it can be replayed and viewed in the historical session list details. Defaults to false. |
| proxy_url | string | Used to set the browser’s proxy URL, for example: http://user:pass@ip:port. If this parameter is set, all other proxy_* parameters will be ignored.- 💡Custom proxy functionality is currently only available to Enterprise and Enterprise Enhanced subscription users Upgrade Now- 💡Enterprise-level custom users can contact us to use custom proxies. |
| proxy_country | string | Sets the target country/region for the proxy, sending requests via an IP address from that region. You can specify a country code (e.g., US for the United States, GB for the United Kingdom, ANY for any country). See country codes for all supported options. |
| fingerprint | string | A browser fingerprint is a nearly unique “digital fingerprint” created using your browser and device configuration information, which can be used to track your online activity even without cookies. Fortunately, configuring fingerprints in Scraping Browser is optional. We offer deep customization of browser fingerprints, such as core parameters like browser user agent, time zone, language, and screen resolution, and support extending functionality through custom launch parameters. Suitable for multi-account management, data collection, and privacy protection scenarios, using scrapeless’s own Chromium browser completely avoids detection. By default, our Scraping Browser service generates a random fingerprint for each session. Reference |5. PNG/JPEG
By adding response_type=png to the request, you can capture a screenshot of the target page and return a png or jpeg image. When the response result is set to png or jpeg, you can set whether the returned result is full screen by using the response_image_full_page=true parameter. The default value of this parameter is false.
The following code example shows how to get a screenshot of a specified area on the Scrapeless homepage. First, we find the CSS selector for the area we want to capture the image.
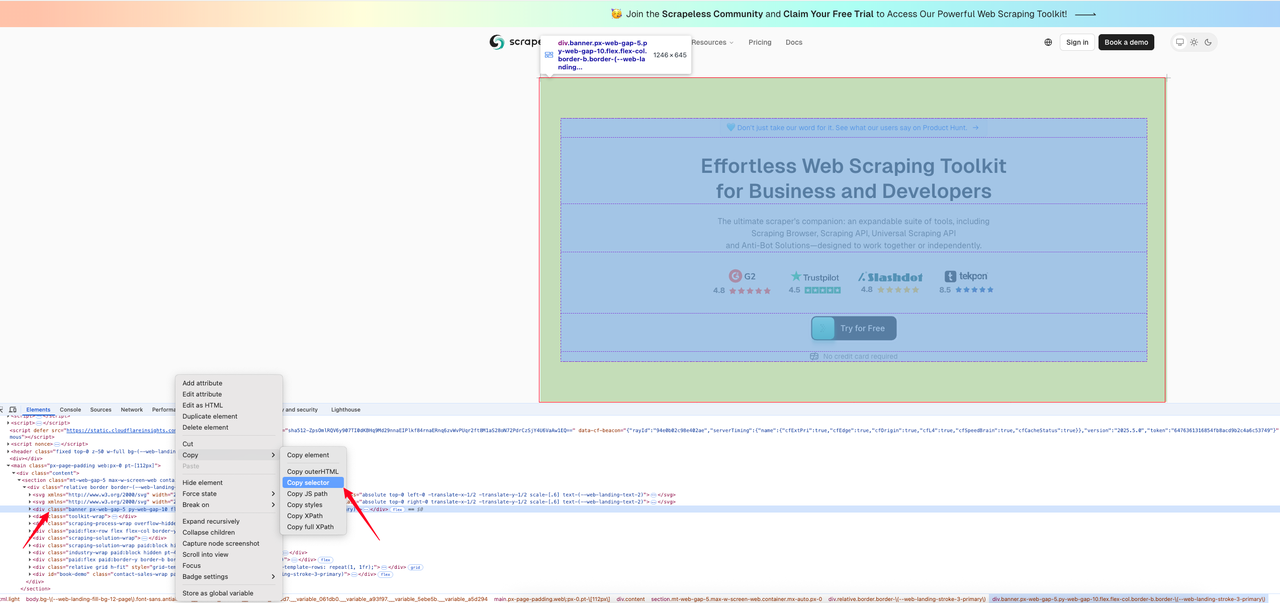
Below is the interception code:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // CSS selector of the page table element
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # CSS selector of the page table element
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- Result of PNG return:

👉 Visit Scrapeless Docs to learn more
👉 Check out the API documentation now: JS Render
Use scenarios are fully covered
This update is especially suitable for:
- Content extraction applications (such as summary generation, intelligence gathering)
- SEO data crawling (such as meta, structured data analysis)
- News aggregation platform (quickly extract text and author)
- Link analysis and monitoring tools (extract href, nofollow information)
Whether you want to quickly crawl text or want structured data, this update can help you get more results with less effort.
Experience it now
The function has been fully launched on Scrapeless. No additional authorization or upgrade plan is required. Just limit the output parameter or pass in the response_type parameter to experience the new data return format!
Scrapeless has always been committed to building an intelligent, stable and easy-to-use web data platform. This update is just another step forward. Welcome your experience and feedback, let us make web data acquisition easier together.
🔗 Try Scrapeless Universal Scraping API now
📣 Join the community to get updates and practical tips in the first place!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


