
How to Scrape Naver Shop Coupon Data
Advanced Data Extraction Specialist
Naver Shop is one of the largest e-commerce platforms in South Korea, offering a wide variety of products and services. One of its most prominent features is the coupon system, which provides users with shopping discounts. For businesses, marketers, and developers, scraping Naver Shop coupon data can offer valuable insights into consumer behavior, pricing strategies, and market trends. However, extracting coupon data from such a dynamic and security-focused platform requires careful planning, advanced tools, and adherence to ethical guidelines.
In this article, we will explore methods for scraping Naver Shop coupon data, including the challenges involved and the most effective solutions. We also recommend using the Scrapeless Naver Scraping API, a powerful tool specifically designed for seamless and efficient data extraction from Naver Shop.
Why Scrape Naver Shop Coupon Data?
Before diving into the technical details, let’s first understand why scraping Naver Shop coupon data is valuable:
(1) Market Research
Trend Analysis : Analyze coupon trends to identify popular product categories or seasonal promotions.
Competitor Monitoring : Track competitors’ coupons to adjust your own pricing and promotional strategies.
Consumer Behavior Insights : Understand how discounts influence purchasing decisions and customer loyalty.
(2) Business Optimization
Dynamic Pricing : Use coupon data to optimize pricing strategies and maintain market competitiveness.
Inventory Management : Identify high-demand products based on coupon usage and adjust inventory accordingly.
Personalized Marketing : Build targeted campaigns by analyzing coupon redemption patterns.
(3) Automation and Scalability
Automate the process of collecting and analyzing coupon data at scale, saving time and resources.
Integrate scraped data into dashboards or CRM systems for real-time insights.
Challenges in Scraping Naver Shop Coupon Data
While scraping Naver Shop coupon data can be highly beneficial, it comes with several challenges that must be addressed:
(1) Anti-Scraping Mechanisms
Naver Shop employs advanced anti-scraping technologies, including:
- CAPTCHA : Prevents automated bots from accessing sensitive pages.
- IP Blocking : Restricts access from suspicious or repeated requests.
- Dynamic Content Loading : Uses JavaScript to dynamically load data, making it difficult for traditional scraping tools to extract information.
(2) Legal and Ethical Issues
- Terms of Service : Violating Naver Shop’s terms of service may lead to legal consequences.
- Data Privacy : Ensuring compliance with data privacy regulations (e.g., GDPR or local laws) is crucial.
(3) Technical Complexity
- Session Management : Handling cookies, headers, and authentication tokens can be challenging.
- Scalability : Scaling up scraping operations to handle large datasets without being detected requires advanced infrastructure.
(4) Maintenance Costs
Websites like Naver Shop frequently update their structure, necessitating constant adjustments to scraping scripts.
How to Scrape Naver Shop Coupon Data
1. Traditional Methods vs. Modern Solutions
(1) Traditional Web Scraping
Traditional methods involve writing custom scripts using tools like BeautifulSoup, Selenium, or Playwright. While these tools are powerful, they come with significant drawbacks:
- High Maintenance : Scripts need frequent updates to adapt to website changes.
- Anti-Scraping Obstacles : CAPTCHA solving, IP rotation, and TLS fingerprinting must be implemented manually.
- Limited Scalability : Scaling up to handle thousands of requests requires substantial resources.
(2) Modern API-Based Solutions
Modern solutions (e.g., Scrapeless Naver Scraping API) eliminate many of the challenges associated with traditional data scraping. The Scrapeless API offers the following features:
- Equipped with robust built-in infrastructure and unlocking capabilities to ensure you can obtain structured data at scale through simple API calls.
- Quickly converts raw HTML into structured data formats like JSON or CSV files.
- Easy to use, simplifying the process of extracting structured data with minimal setup.
- Fully compatible with major programming languages and tools.
2. How to Scrape Naver Shop Coupon Data Using Scrapeless Naver Scraping API
Scrapeless advocates for the lawful and compliant scraping of publicly available data. Please ensure that the information you obtain is used only for legitimate purposes and avoid any form of profit-driven usage. Strictly adhere to relevant laws, regulations, and scraping rules to help maintain a healthy data ecosystem.
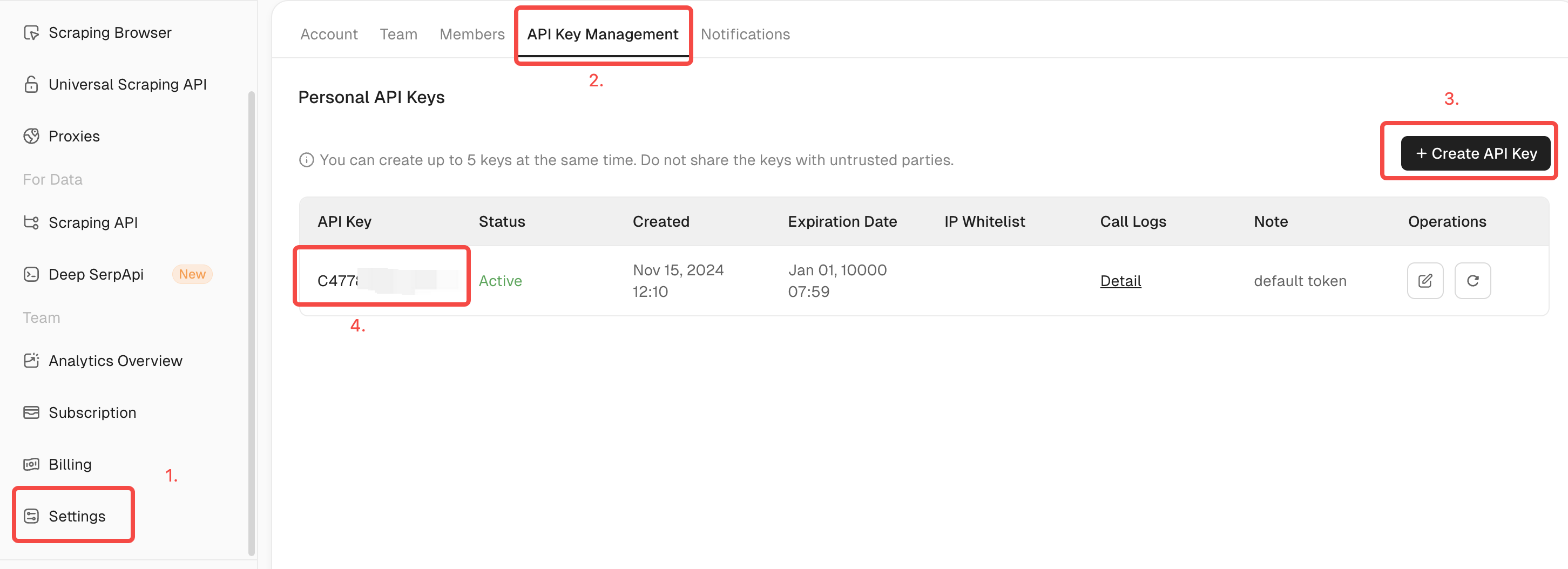
Step 1: Set Up Your Scrapeless Account
- Register for a free account on Scrapeless.
- Obtain your API key from the dashboard. This key will be used to authenticate your requests.
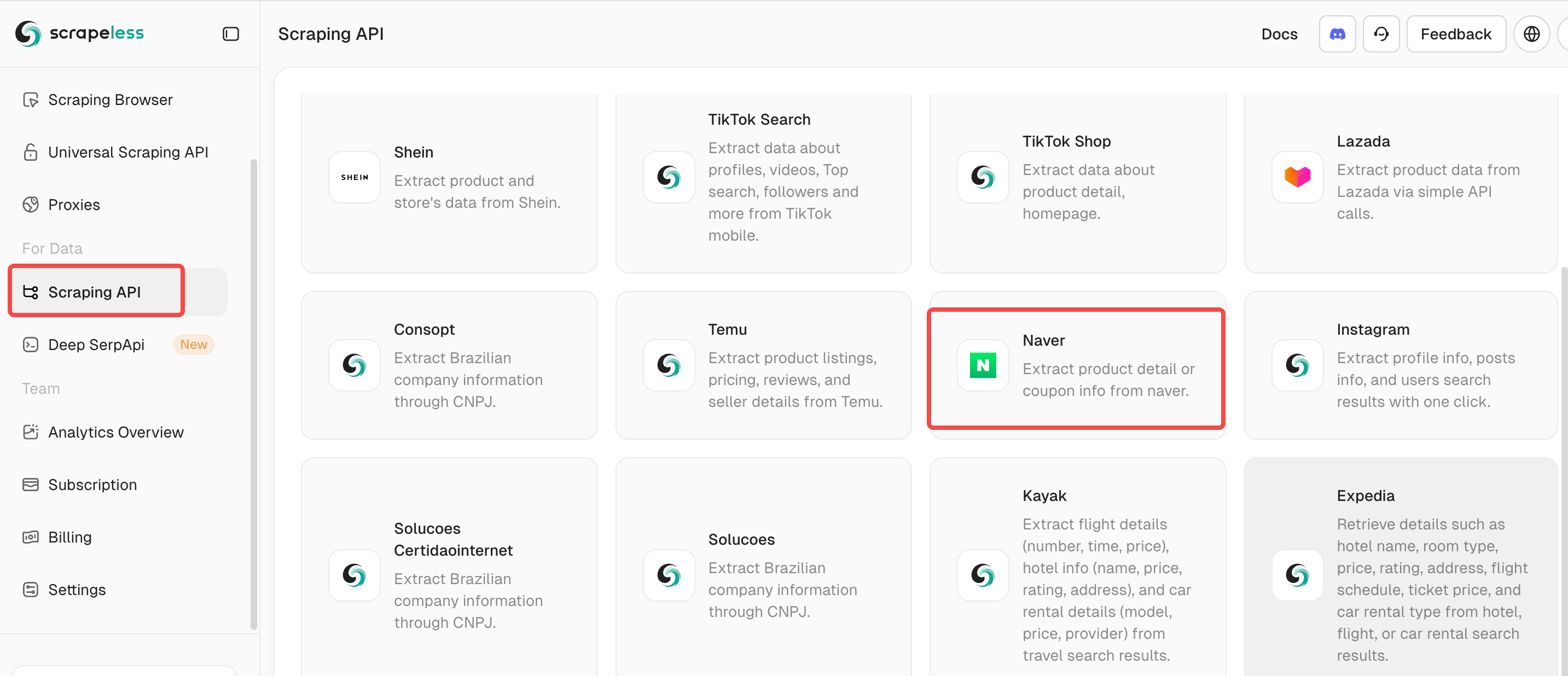
Step 2: Select Naver and enter the crawler dashboard interface.
Step 3: Set scraping parameters
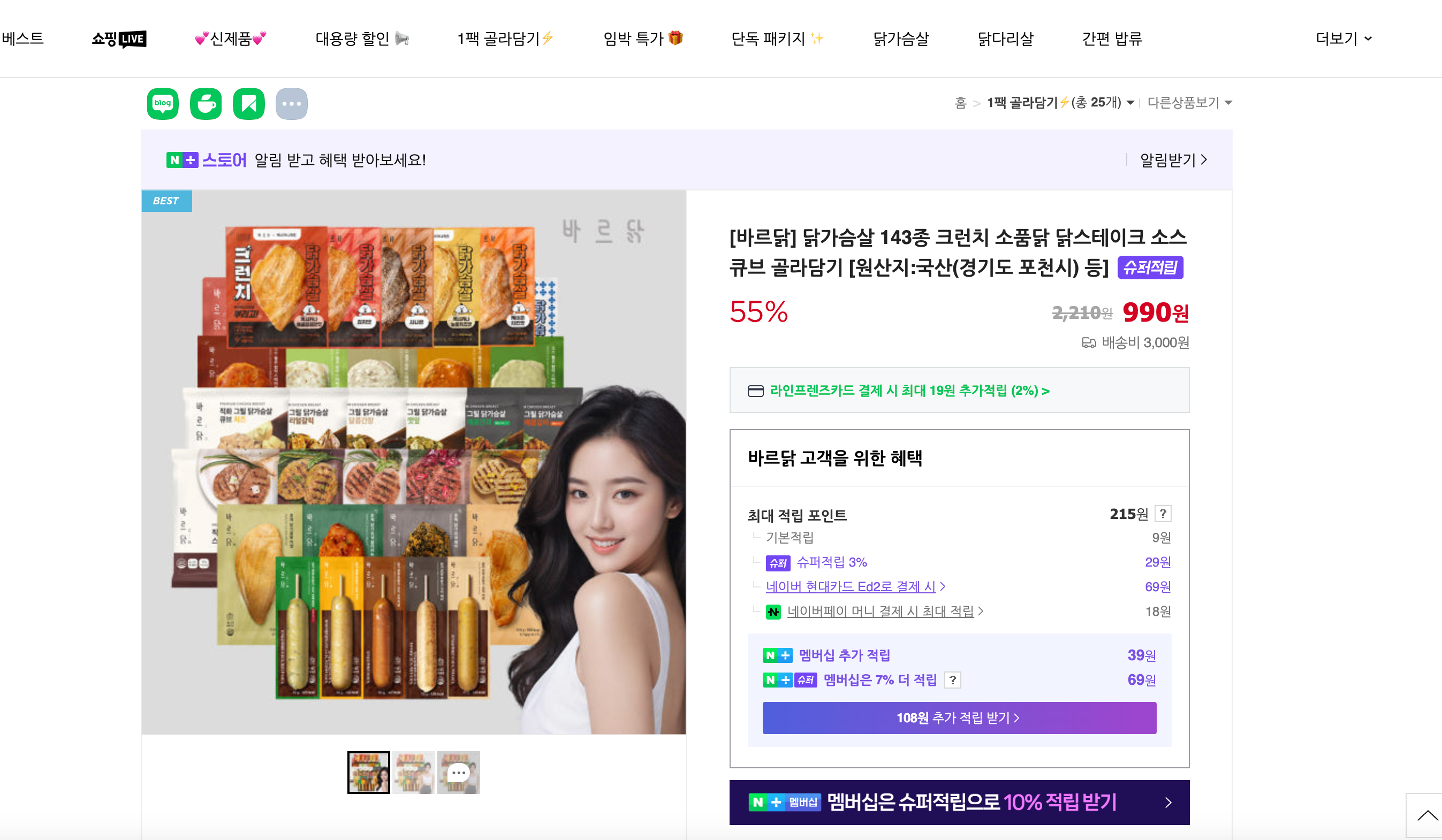
Product ID and Store ID can be found directly in the product URL. Let's take: [바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등] as an example:
- Store ID: barudak
- Product ID: 4469033180
Step 4: Scrape basic product information
- After setting the necessary scraping parameters, click "Start Scraping" and the scraping results will be displayed on the right.
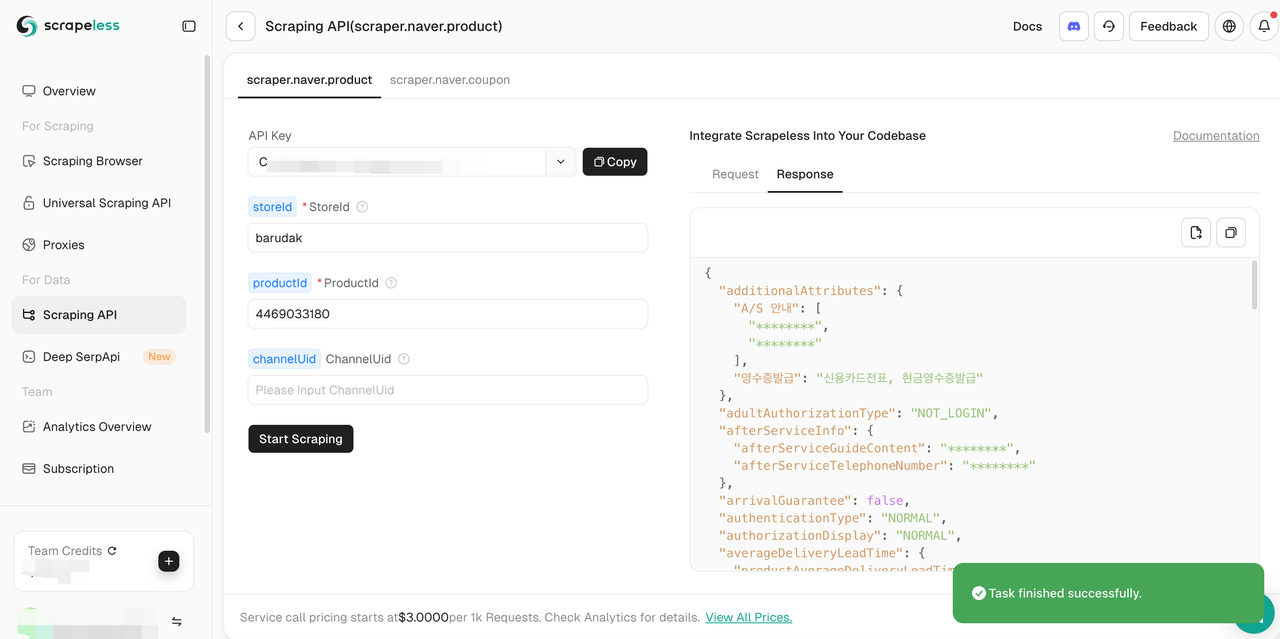
The following are some examples of the crawled results:
{"additionalAttributes": {"A/S 안내": ["********","********"],"영수증발급": "신용카드전표, 현금영수증발급"},"adultAuthorizationType": "NOT_LOGIN","afterServiceInfo": {"afterServiceGuideContent": "********","afterServiceTelephoneNumber": "********"},"arrivalGuarantee": false,"authenticationType": "NORMAL","authorizationDisplay": "NORMAL","averageDeliveryLeadTime": {"productAverageDeliveryLeadTime": 1.6511627,"sellerAverageDeliveryLeadTime": 1.6331967},"benefitsPolicy": {"givePresent": true,"managerBankbookAccumulatePolicyNo": 12306300388384,"managerBankbookAccumulateValue": 0.5,"managerBankbookAccumulateValueUnit": "PERCENT","managerMaxBankbookAccumulateAmount": 10000,"managerMaxPaymoneyAccumulateAmount": 30000,"managerMaxPurchasePointAmount": 100000,"managerPaymoneyAccumulatePolicyNo": 439583905,"managerPaymoneyAccumulateValue": 1.5,"managerPaymoneyAccumulateValueUnit": "PERCENT","managerPurchasePointPolicyNo": 10511031105304,"managerPurchasePointValue": 1,"managerPurchasePointValueUnit": "PERCENT","sellerImmediateDiscountPolicyNo": "SE_4460099867","sellerImmediateDiscountValue": 1220,"sellerImmediateDiscountValueUnit": "WON"},"benefitsView": {"afterUsePhotoVideoReviewPoint": 0,"afterUseTextReviewPoint": 0,"discountedRatio": 55,"discountedSalePrice": 990,"generalPurchaseReviewPoint": 0,"givePresent": true,"managerAfterUsePhotoVideoReviewPoint": 0,"managerAfterUseTextReviewPoint": 0,"managerArrivalGuaranteePoint": 0,"managerBankbookAccumulatePoint": 4,"managerGeneralPurchaseReviewPoint": 50,"managerImmediateDiscountAmount": 0,"managerMembershipArrivalGuaranteePoint": 0,"managerPaymoneyAccumulatePoint": 14,"managerPhotoVideoReviewPoint": 150,"managerPremiumPurchaseReviewPoint": 150,"managerPurchaseExtraPoint": 0,"managerPurchasePoint": 9,"managerTextReviewPoint": 50,"mobileDiscountedRatio": 55,"mobileDiscountedSalePrice": 990,"mobileManagerArrivalGuaranteePoint": 0,"mobileManagerBankbookAccumulatePoint": 4,"mobileManagerImmediateDiscountAmount": 0,"mobileManagerMembershipArrivalGuaranteePoint": 0,"mobileManagerPaymoneyAccumulatePoint": 14,"mobileManagerPurchaseExtraPoint": 0,"mobileManagerPurchasePoint": 9,"mobileSellerCustomerManagementPoint": 0,"mobileSellerImmediateDiscountAmount": 1220,"mobileSellerPurchasePoint": 0,"photoVideoReviewPoint": 0,"premiumPurchaseReviewPoint": 0,"sellerCustomerManagementPoint": 0,"sellerImmediateDiscountAmount": 1220,"sellerPurchasePoint": 0,"specialDiscountAmount": {},"storeMemberReviewPoint": 0,"textReviewPoint": 0},"best": false,"cardPromotions": [],"category": {"category1Id": "50000006","category1Name": "식품","category2Id": "50000145","category2Name": "축산물","category3Id": "50001172","category3Name": "닭고기","category4Id": "50013800","category4Name": "닭가슴살","categoryId": "50013800","categoryLevel": 4,"categoryName": "닭가슴살","exceptionalCategoryTypes": ["FREE_RETURN_INSURANCE","ORIGINAREA_PRODUCTS","REGULAR_SUBSCRIPTION","REVIEW_UNEXPOSE","GROUP_PRODUCT_MAX"],Step 5: Crawl Naver product coupon information
From the above crawling results, we can see the following information:
In the JSON data, the value of productNo is:
"productNo": "4460099867"
In addition, you can also find other unique identifiers related to products, such as:
- "productId": "10217226674"
- categoryId: 50013800 corresponds to the category 닭가슴살
- "wholeCategoryId": "50000006>50000145>50001172>50013800",
- "channelUid": "2sWDx0OygJl5sQcE9f6rD"
After setting the crawling parameters, you can crawl to get the results.
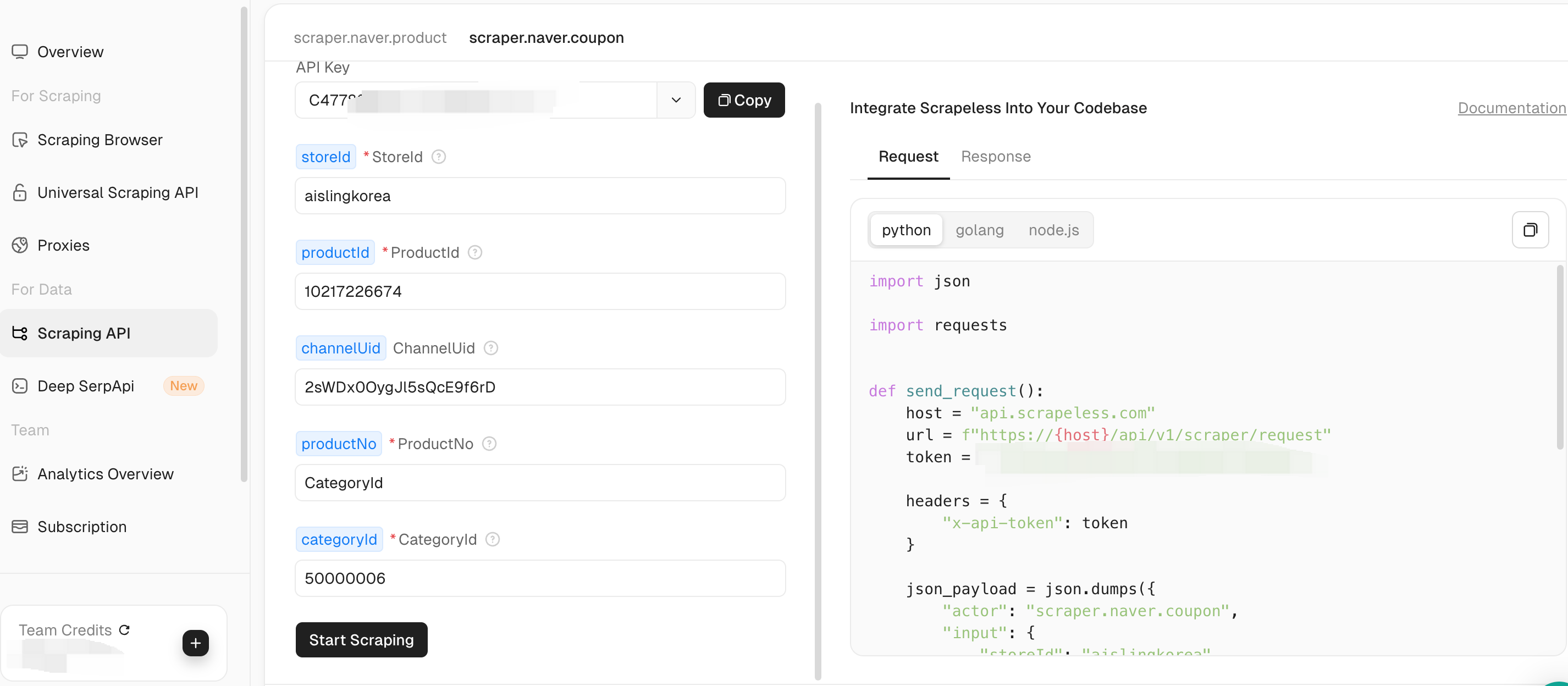
Use Scrapeless Naver Scraping API to get coupon data. The following is a Python request code example:
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR SCRAPELESS API KEY"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.coupon",
"input": {
"storeId": "aislingkorea",
"productId": "10217226674",
"channelUid": "2sWE0veQFZEVUJKUPvNin",
"productNo": "10167996176",
"categoryId": "50002398"
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()You just need to replace the token part with your API KEY.
How to Bypass Naver Shop's Anti-Bot Measures
Scrapeless provides premium global clean IP proxy services, specializing in dynamic residential IPv4 proxies. With over 70 million IPs across 195 countries, the Scrapeless residential proxy network offers comprehensive global proxy support to drive your business growth.
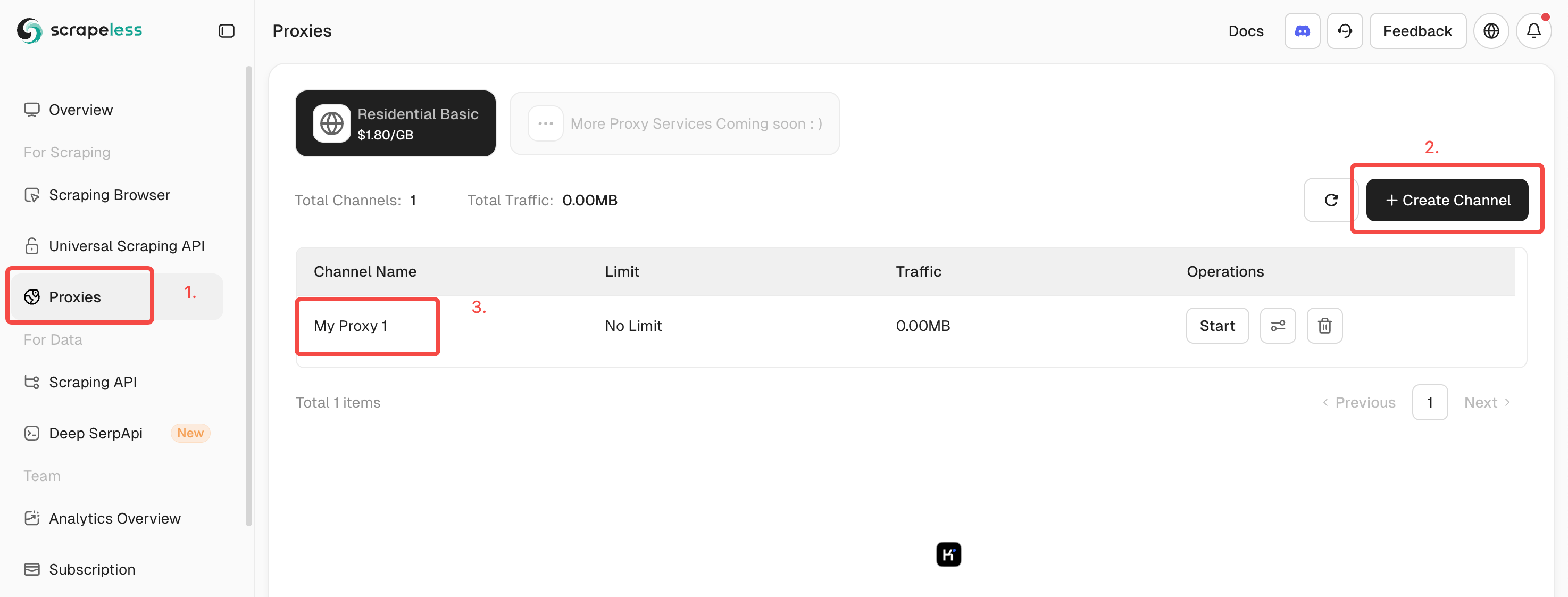
Steps to Obtain Proxies:
- Step 1 : Log in to Scrapeless.
Step 2 : Click on "Proxies" and create a channel.
Step 3. Click "Start", then fill in the information you need in the action box, and then click "Generate". Wait a moment, and you will see the rotating proxy we generated for you on the right. Now click "Copy" to use it.
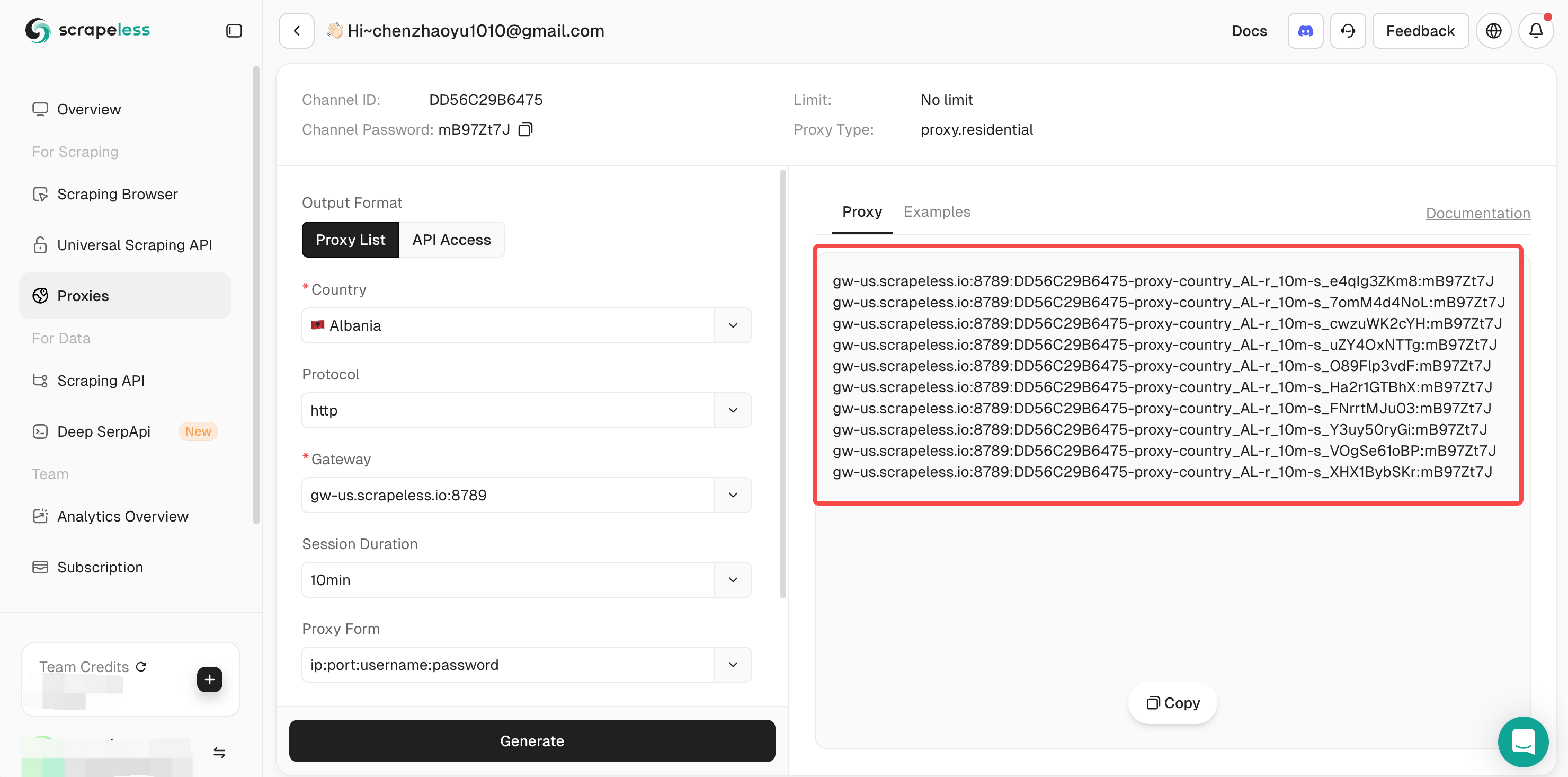
Or you can integrate our proxy code into your project:
1. Code:
curl --proxy host:port --proxy-user username:password API_URL2. Browser:
- Selenium
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
const puppeteer =require('puppeteer');
(async() => {const proxyUrl = 'http://gw-us.scrapeless.com:8789';const username = 'username';const password = 'password';
const browser = await puppeteer.launch({args: [`--proxy-server=${proxyUrl}`],headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });await page.goto('API_URL');
await browser.close();
})();Summary
In summary, scraping Naver Shop's coupon data can provide valuable insights for merchants, marketers, and developers, whether it is analyzing market trends, optimizing pricing strategies, or formulating promotion plans, these data can play an important role. However, in the face of complex anti-crawling mechanisms, dynamic content loading, and legal compliance, it is crucial to choose an efficient and reliable tool. Scrapeless stands out for its powerful functions and ease of use, providing users with a one-stop solution.
Learn more about Scrapeless
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


