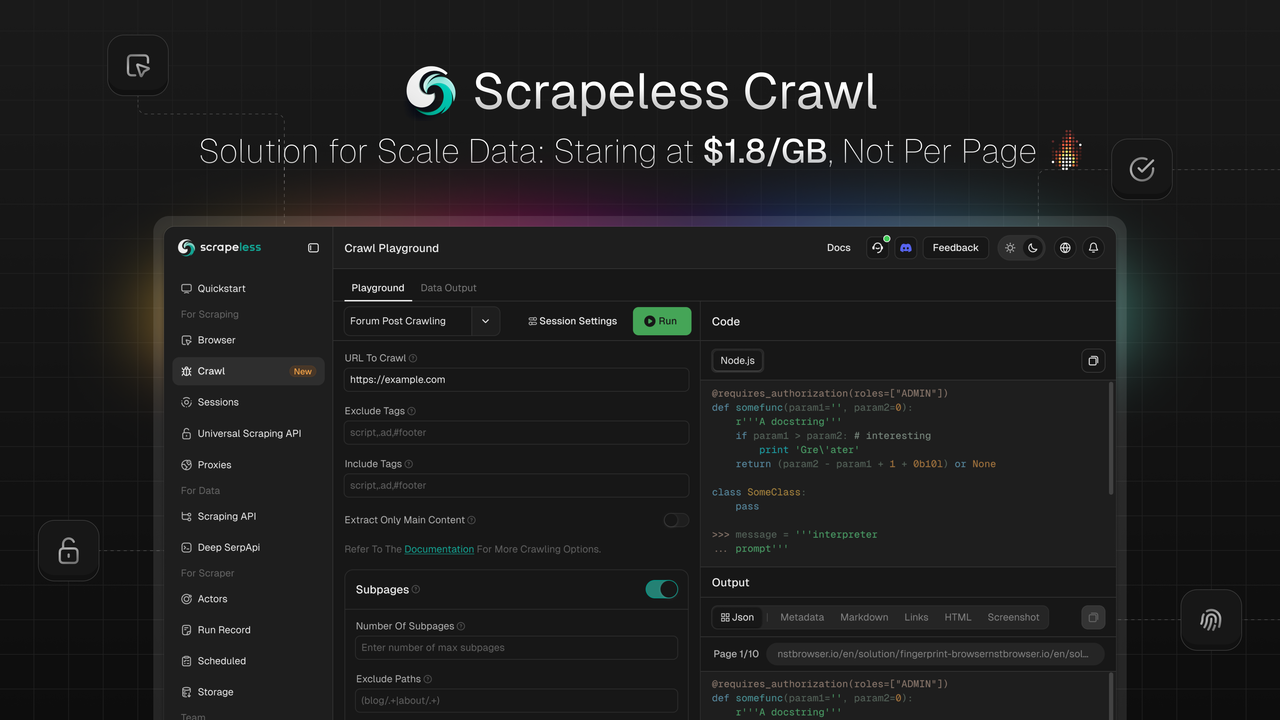
What Is Scrapeless Crawl & How Does It Work?
Senior Web Scraping Engineer
Scrapeless is thrilled to launch Crawl, a feature purpose-built for large-scale data scraping and processing. Crawl stands out with its core advantages of intelligent recursive scraping, bulk data processing capabilities, and flexible multi-format output, empowering enterprises and developers to rapidly acquire and process massive web data—fueling applications in AI training, market analysis, business decision-making, and beyond.
💡Coming Soon: Data extraction & summarization via AI LLM Gateway, with seamless integration for open-source frameworks and visual workflow integrations—solving web content challenges for AI developers.
What is Crawl
Crawl is not just a simple data scraping tool but a comprehensive platform that integrates both scraping and crawling functionalities.
-
Bulk Crawling: Supports large-scale single-page crawling and recursive crawling.
-
Multi-Format Delivery: Compatible with JSON, Markdown, Metadata, HTML, Links, and Screenshot formats.
-
Anti-Detection Scraping: Our independently developed Chromium kernel, enables high customization, session management, and anti-detection capabilities, like fingerprint config, CAPTCHA solving, stealth mode, and proxy rotation to bypass website blocks.
-
Self-developed Chromium-Driven: Powered by our Chromium kernel, enables high customization, session management, and auto CAPTCHA solving.
1. Auto CAPTCHA Solver: Automatically handles common CAPTCHA types, including reCAPTCHA v2 and Cloudflare Turnstile/Challenge.
2. Session Recording and Replay: Session replay helps you easily check actions and requests via recorded playback, reviewing them step by step to quickly understand operations for problem-solving and process improvement.
3. Concurrency Advantage: Unlike other crawlers with strict concurrency limits, Crawl’s basic plan supports 50 concurrency, with unlimited concurrency in the premium plan.
4. Cost Saving: Outperforming competitors on websites with anti-crawl measures, it offers significant advantages in free captcha resolution — expected saving 70% cost.
Leveraging advanced data scraping and processing capabilities, Crawl ensures the delivery of structured real-time search data. This empowers enterprises and developers to always stay ahead of market trends, optimize data-driven automation workflows, and rapidly adjust market strategies.
Solve Complex Data Challenges with Crawl: Faster, Smarter, and More Efficient
For developers and enterprises in need of reliable web data at scale, Crawl also delivers:
✔ High-Speed Data Scrape – Retrieve data from multiple web pages in a matter of seconds
✔ Seamless Integration– Soon integrate with open-source frameworks and visual workflow integrations, such as Langchain, N8n, Clay, Pipedream, Make and etc.
✔ Geo-targeting Proxies – Built-in Proxie support 195 countries
✔ Session Management – Intelligently manage sessions and view LiveURL sessions in real-time
How to Use Crawl
The Crawl API simplifies data scrape by either fetching specific content from web pages in a single call or recursively crawling an entire site and its links to gather all available data, supported in multiple formats.
Scrapeless provides endpoints to initiate scrape requests and check their status/results. By default, scraping is asynchronous: start a job first, then monitor its status until completion. However, our SDKs include a simple function that handles the entire process and returns the data once the job finishes.
Installation
Install the Scrapeless SDK using NPM:
Bash
npm install @scrapeless-ai/sdkInstall the Scrapeless SDK using PNPM:
Bash
pnpm add @scrapeless-ai/sdkCrawl Single Page
Crawl specific data (e.g., product details, reviews) from web pages in one call.
Usage
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new Scrapeless({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();Browser Configurations
You can customize session settings for scraping, such as using proxies, just like creating a new browser session.
Scrapeless automatically handles common CAPTCHAs, including reCAPTCHA v2 and Cloudflare Turnstile/Challenge—no extra setup needed, for details, see captching solving.
To explore all browser parameters, check the API Reference or Browser Parameters.
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new Scrapeless({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Scrape Configurations
Optional parameters for the scrape job include output formats, filtering to return only main page content, and setting a maximum timeout for page navigation.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();For a full reference on the scrape endpoint, check out the API Reference
Batch Scrape
Batch Scrape works the same as regular scrape, except instead of a single URL, you can provide a list of URLs to scrape at once.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Crawl Subpage
The Crawl API supports recursively crawling a website and its links to extract all available data.
For detailed usage, check out the Crawl API Reference.
Usage
Use recursive crawling to explore an entire domain and its links, extracting every piece of accessible data.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Response
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "Example Page",
"description": "A sample webpage"
},
"markdown": "# Example Page\nThis is content...",
...
},
...
]
}Each crawled page has its own status of completed or failed and can have its own error field, so be cautious of that.
To see the full schema, check out the API Reference.
Browser Configurations
Customizing session configurations for scrape jobs follows the same process as creating a new browser session. Available options include proxy configuration. To view all supported session parameters, consult the API Reference or Browser Parameters.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Scrape Configurations
Parameters may include output formats, filters to return only main page content, and maximum timeout settings for page navigation.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Initialize the client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Get your API key from https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();For a full reference on the crawl endpoint, check out the API Reference.
Exploring the Diverse Use Cases of Crawling
A built-in playground is available for developers to test and debug their code, and you can utilize Crawl for any scraping needs, for example:
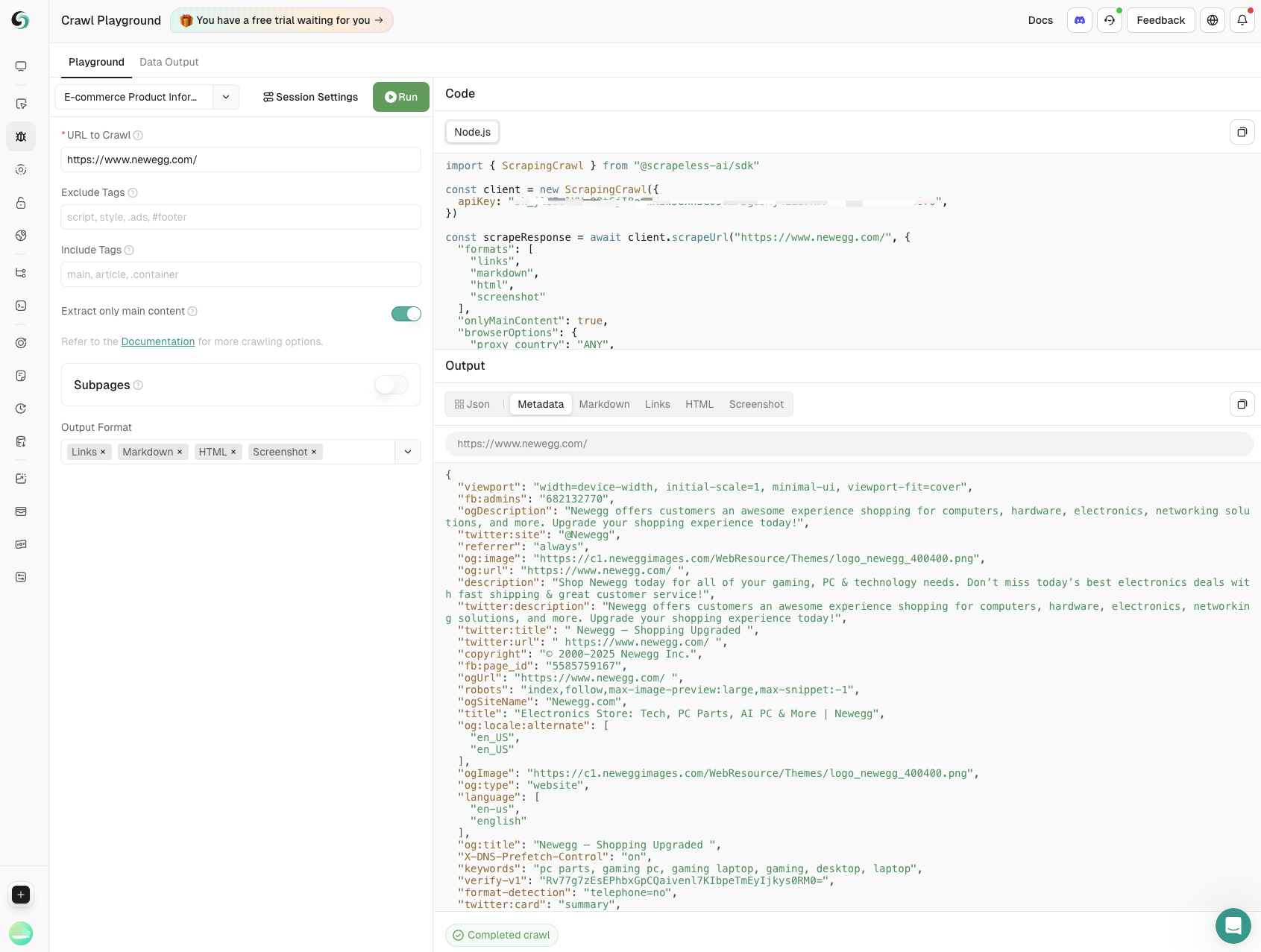
- Product Information Scraping
Key data including product names, prices, user ratings, and review counts are extracted by scraping on E-commerce websites. Fully supports product monitoring and aids businesses to make informed decisions.
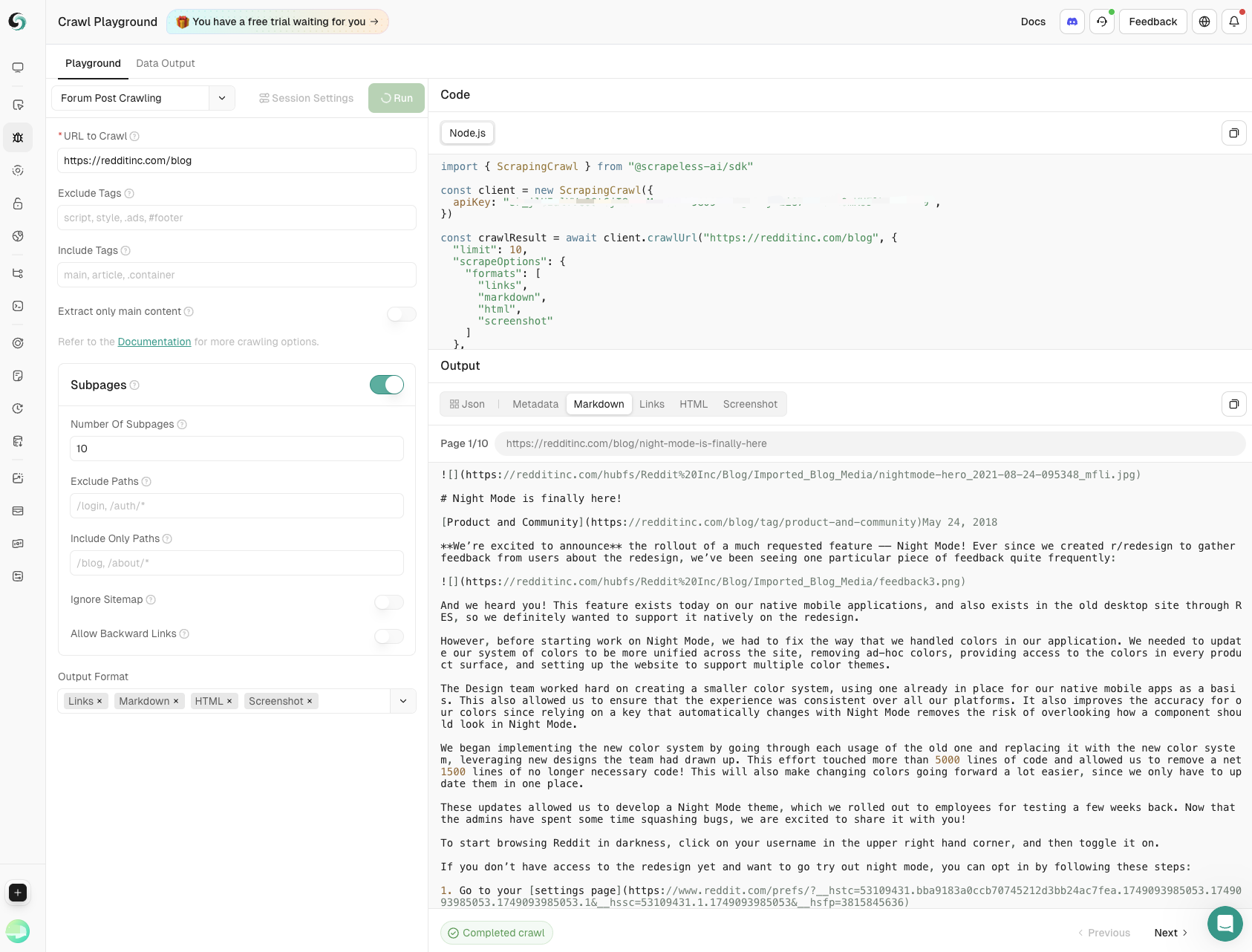
- Forum Post Crawling
Capture main post content and subpage comments with precise control over depth and breadth, ensuring comprehensive insights from community discussions.
Enjoy Crawl and Scrape Now!
Cost-Efficient and Affordable for any needs: Starts at $1.8/GB, Not Per Page
Outperform competitors with our Chromium-based scraper featuring a pricing model that combines proxies volume and hourly rate, delivering up to 70% cost savings on large-scale data projects compared to page-count models.
Register for a Trial Now and Get the Robust Web Toolkit.
💡For high-volume users, contact us for customized pricing – competitive rates tailored to your needs.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


