
Scrapeless Scraping Browser: A high-concurrency automation solution for AI
Advanced Data Extraction Specialist
Introduction: Upgrading the Concurrency Capabilities of Scrapeless Scraping Browser
As the developers and founding team behind Scrapeless, we are driven by a sincere passion for the future of AI automation. Our mission is to create an automated browser truly "designed for AI." Over the past few years, from Browserless.io to the numerous cloud vendors launching "Browser as a Service" (BaaS), the market has proven that AI Agents urgently need a new interaction medium—a cloud-based browser specifically designed for AI. For example, Auto-GPT can autonomously search for the best flights on Booking.com or automatically submit survey responses in Google Forms. Similarly, ChainGPT’s intelligent customer service system can log into e-commerce backends in real-time to retrieve order data and complete multi-step operations. Behind these capabilities lies an extreme pursuit of high concurrency and "human-like" simulation.
However, we have observed that existing solutions often stumble at two critical points:
1. High-Concurrency Scaling: When hundreds or thousands of proxy tasks simultaneously target a site, a single node quickly becomes a bottleneck.
2. Realistic Browsing Behavior: Multi-dimensional disguises such as fingerprint rotation, TLS characteristics, and mouse trajectories—if not precise enough—can be instantly flagged by the risk control systems of e-commerce platforms and social media.
With these challenges in mind, we focused on two key areas during the product design phase:
-
Cloud Elastic Scaling: Scrapeless supports seamless scaling from tens to unlimited concurrent sessions, ensuring zero queuing and zero timeouts even during peak task loads.
-
Full-Stack Human-Like Protection: By deeply customizing the Chromium kernel, Scrapeless achieves multi-dimensional fingerprint obfuscation, controllable TLS handshake strategies, and progressive mouse/keyboard simulations, making it nearly impossible for target websites to detect anomalies.
What makes this even more remarkable is that while delivering top-tier performance, we have reduced costs to 70% of industry-standard solutions, helping developers save 60%-80% on expenses for large-scale testing and long-running tasks. Whether you need to monitor thousands of SKUs through daily scraping or drive thousands of customer service bots across multiple sites, Scrapeless provides the most reliable and cost-effective infrastructure.
In the following sections, we will delve into the pricing advantages, core functionalities, and future roadmap of Scrapeless Scraping Browser, giving you a comprehensive understanding of why it is the ultimate choice for the "Browser for AI" era.
Scrapeless Scraping Browser Price Comparison Analysis
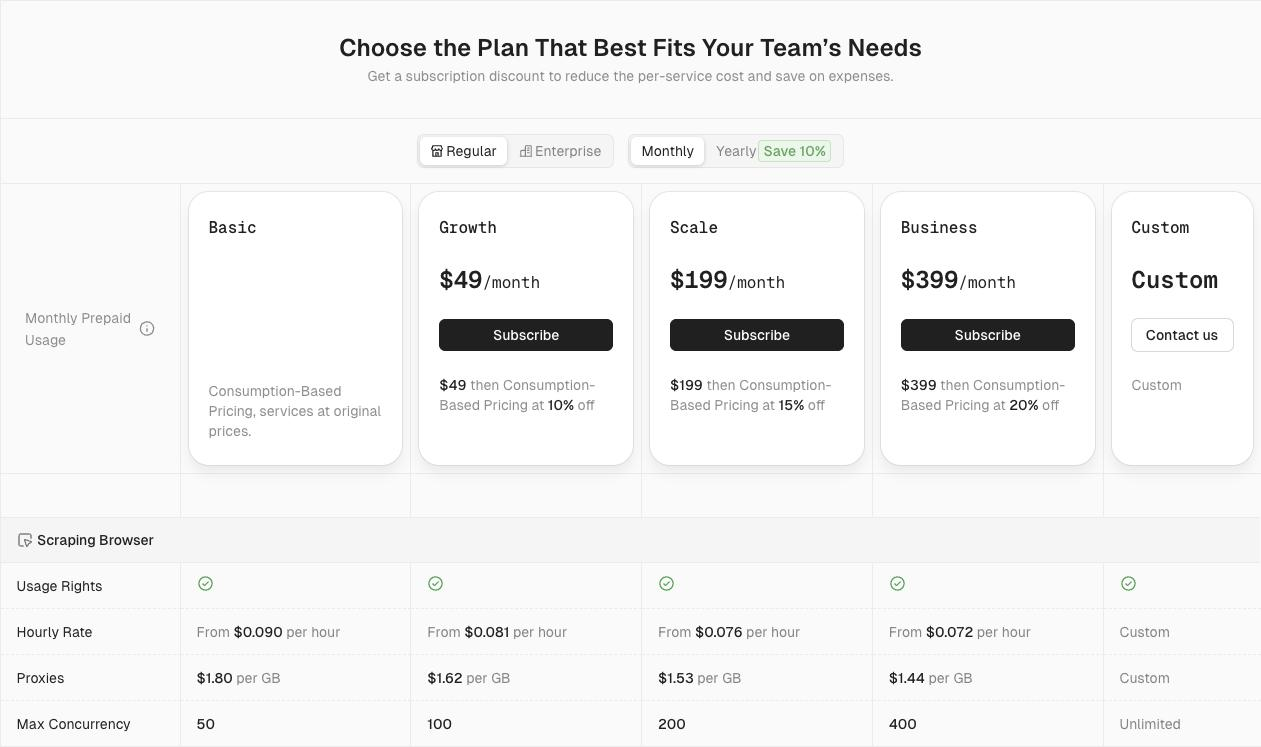
1. Comparison of Hourly Rates and Proxy Fees
The following is a comparison of the price ranges for hourly rates and proxy fees among competing products. We have distilled the approximate pricing ranges to help users quickly understand Scrapeless's cost-performance advantage.
Table: Price Range Comparison
| Tool Name | Hourly Rate Range (USD/hour) | Proxy Fee Range (USD/GB) | Concurrency Support | Remarks |
|---|---|---|---|---|
| Scrapeless | $0.063 – $0.090 / hour (varies based on concurrency and usage) | $1.26 - $1.80 / GB | 50 / 100 / 200 / 400 / 600 / 1000 / Unlimited | - Custom proxies supported - Free CAPTCHA solving for Cloudflare, reCAPTCHA, AWS WAF; future support for Imagetotext CAPTCHA - Rates vary based on actual usage |
| Browserbase | $0.10 – $0.198 / hour (includes 2-5GB free proxy) | $10 / GB (after free quota) | 3 (Basic) / 50 (Advanced) | - Custom proxies supported |
| Brightdata | $0.10 / hour | $9.5 / GB (Standard); $12.5 / GB (Premium Domains) | Unlimited | - Custom proxies not supported - Actual concurrency sessions may be affected by: - Account plan and usage limits - Available bandwidth and system resources - Billing settings and credit balance |
| Zenrows | $0.09 / hour | $2.8 - $5.42 / GB | Up to 100 | - Custom plans available at $2.8 / GB - Business plan supports up to 100 concurrency |
| Browserless | $0.084 – $0.15 / hour (billed per "Unit") | $4.3 / GB | 3 / 10 / 50 | - Custom proxies supported - $7 per 1000 hCaptcha and reCaptcha solves - Each "Unit" equals 0.00833 hours of browser time - Cloudflare bypass included for free |
2. Price Comparison in Concurrent Scenarios
To more intuitively demonstrate Scrapeless's pricing advantage, we compare it through typical usage scenarios.
Case 1: Single Request (1 Browser Instance)
Assume a user initiates a single request (e.g., logging into ChatGPT), lasting 1 hour and consuming 1GB of traffic:
Scrapeless (based on standard package rates):
- Hourly rate: $0.072
- Proxy fee: $1.44
- Total cost = 0.072 + 1.44 = $1.512
Competitor (using Brightdata as an example):
- Hourly rate: $0.10
- Proxy fee: $9.5 (standard)
- Total cost = 0.10 + 9.5 = $9.6
Cost Advantage: Scrapeless saves approximately 84.25% of the cost.
Case 2: Large-Scale Concurrent Scenario (100 Browser Instances)
A user of Scrapeless is building an LLM-based marketing ranking monitoring system to scrape data from multiple websites in real-time and generate dynamic ranking reports. Their current business requirements demand running 100 browser instances simultaneously , lasting 1 hour , and consuming 40GB of traffic .
Scrapeless (based on standard package rates):
- Hourly rate: 0.072 × 100 = 7.2
- Proxy fee: 1.44 × 40 = 57.6
- Total cost = 7.2 + 57.6 = $64.8
Competitor (using Zenrows as an example):
- Hourly rate: 0.09 × 100 = 9
- Proxy fee: 2.8 × 40 = 112
- Total cost = 9 + 112 = $121
Cost Advantage: Scrapeless saves approximately 46.45% of the cost.
This user conducted a detailed price and performance comparison of mainstream browser automation tools during the project's early stages. They found that many competitors had the following issues when handling large-scale concurrent tasks:
- Insufficient high-concurrency support: Most tools have low maximum concurrency limits, unable to meet the requirement of 100 instances.The user’s future concurrency needs will exceed 500, and few products on the market can support this level of demand.
- High additional fees: Some products charge extra for high-concurrency tasks, causing overall costs to skyrocket.
- Limited technical support: When encountering CAPTCHA or anti-scraping mechanisms, some tools lack built-in solutions, increasing development complexity.
After a comprehensive evaluation, the user ultimately chose Scrapeless Scraping Browser. They stated that Scrapeless not only offers significant cost advantages (saving nearly 47% of the cost) but also ensures the efficiency and reliability of their data scraping system.
Scrapeless Scraping Browser: Cloud-Based Browser Automation for AI Agents
Scrapeless Scraping Browser is a cloud-based browser automation tool designed for data scraping, AI Agents, and proxy systems. It provides a real browser environment through deep simulation technology at the Chrome kernel level, supporting dynamic fingerprint obfuscation and TLS fingerprint spoofing to ensure highly human-like user behavior. Additionally, it is fully user-controlled, does not store any data, ensuring compliance and privacy protection.
Technical Advantages
1. Real Browser Environment
- Chrome Kernel Support : Provides a complete browser environment, simulating real user behavior.
- TLS Fingerprint Spoofing : Breaks traditional anti-scraping mechanisms by forging TLS fingerprints, disguising as a regular browser.
- Dynamic Fingerprint Obfuscation : Dynamically adjusts browser environment variables (e.g., User-Agent, Canvas, WebGL) to enhance human-like behavior and bypass advanced anti-scraping strategies.
2. Cloud Deployment and Scalability
- Cloud Architecture : Fully cloud-based, eliminating the need for local resources and enabling seamless global distributed deployment.
- High Concurrency Support : Supports unlimited parallel tasks, suitable for large-scale data scraping and complex automation scenarios.
- Easy Integration : Seamlessly integrates with existing automation frameworks (e.g., Playwright, Puppeteer) without requiring code refactoring.
3. Designed Specifically for AI Agents
- Automated Proxy Support : Provides robust proxy functionality to help AI Agents perform complex browser automation tasks.
- Flexible Invocation : Supports multi-task parallel processing, making it an ideal tool for building intelligent proxy systems and AI-driven applications.
Core Features
The core competitiveness of Scrapeless Scraping Browser lies in its powerful functionality and flexibility, particularly excelling in the following three areas:
(1) CAPTCHA Solving Capability
Scrapeless Scraping Browser includes advanced CAPTCHA-solving capabilities, automatically handling mainstream CAPTCHA types such as reCAPTCHA and Cloudflare Turnstile.
- Industry-Leading Success Rate : Scrapeless offers a highly efficient CAPTCHA solution with a success rate of over 98%.
- No Extra Fees : While most competitors charge additional fees for CAPTCHA solving, Scrapeless integrates this feature into its base service at no extra cost.
- Real-Time Processing : The CAPTCHA-solving engine completes tasks in milliseconds, ensuring smooth task execution.
(2) Tool Integration Support
- Comprehensive Automation Tool Support : Scrapeless supports popular browser automation tools like Puppeteer and Playwright, enabling developers to integrate quickly.
- AI Integration Capability : Scrapeless is planning deep integration with Browser Use, Computer Use, and LangChain, exploring further capabilities of large language models (LLMs) to expand AI-driven dynamic web interaction use cases.
- Ease of Use : Detailed documentation and example code are provided to help users get started quickly.
(3) Concurrency Support
- Flexible Concurrency Capability : Scrapeless supports concurrency ranging from 50 to unlimited, catering to both small tasks and large-scale automation needs.
- No Extra Fees : While competitors often charge additional fees for high-concurrency scenarios, Scrapeless offers a transparent and flexible pricing model.
Future Plans for Scrapeless Scraping Browser
In the future, Scrapeless Scraping Browser will continue to optimize its core functionalities to meet diverse needs, from basic scraping to complex AI-driven automation, providing users with even more powerful tools. Below are our key areas of focus for updates:
1. Core Functionality Enhancements
- Fingerprint Configuration : Supports flexible configuration of environment variables such as time zone, language, User-Agent, and screen resolution to enhance human-like behavior.
- Proxy Routing Rules : Introduces custom proxy routing functionality, allowing traffic to be directed to different proxies based on domain or location. Provides Session API for session management.
2. Debugging and Monitoring
- Live View : Offers a real-time view in Playground for easy debugging and task takeover.
- Session Management : Supports session replay, inspectors, and metadata queries to enhance task monitoring capabilities.
3. File Handling
- Upload : Easily upload files to target websites using Playwright, Puppeteer, or Selenium.
- Download : Downloaded files are automatically stored in the cloud, with Unix timestamps appended to filenames (e.g., sample-1719265797164.pdf) to avoid conflicts.
- Retrieval : Files can be quickly retrieved via API, suitable for scenarios like data scraping and report generation.
4. Context API and Extension Support
- Context API : Introduces context session persistence to optimize login and multi-step automation scenarios.
- Extension Support : Enhance your browser sessions by loading your own Chrome extensions.
5. Metadata Query
- Use custom tags and query sessions with metadata.
6. SDK and API Upgrades
- Session API : Provides session management functionality to simplify task operations.
- CDP Event Optimization : Expands CDP support, including features like fetching page HTML, clicking elements, scrolling, and taking screenshots.
Summary
Current browser automation tools face numerous challenges when empowering AI-driven scenarios:
- High-concurrency bottlenecks cause task failures.
- Insufficient human-like behavior makes it easy for anti-scraping mechanisms to detect automation.
- High costs limit the feasibility of large-scale tasks.
- Complex integration creates a steep learning curve and leads to inefficiencies.
Scrapeless Scraping Browser redefines "Browser for AI" with three key innovations:
- Cloud Elastic Scaling : Supports seamless scaling from tens to unlimited concurrent sessions, fully unlocking high-throughput potential.
- Full-Stack Human-Like Protection : Deep customization of the Chromium kernel provides fingerprint obfuscation, TLS handshake strategies, and progressive behavioral simulation, effortlessly bypassing anti-scraping restrictions.
- Unmatched Cost Efficiency and Compatibility : Reduces costs by 60%-80% compared to other solutions while maintaining compatibility with Playwright and Puppeteer, lowering the development barrier.
We are also actively exploring next-generation technologies centered around AI. We warmly welcome developers and teams to share optimization suggestions or feature requests for our product. Your feedback is crucial and will help us continuously improve Scrapeless Scraping Browser, providing you with an even better experience.
Learn More About Scrapeless
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


