Scrapeless Playground Is Live – Visual Control for Scraping Browser!
Advanced Data Extraction Specialist
To further enhance the experience of developers using Scrapeless Scraping Browser for web scraping and browser automation, we are excited to announce the official launch of Scrapeless Playground!
Now you can combine the power of Scraping Browser with a fully visual, interactive Playground interface.
Why Did We Build the Playground?
Scrapeless Scraping Browser already offers a powerful and stable automation environment with support for JavaScript rendering, dynamic content handling, fingerprint customization, and more.
However, we heard a few recurring requests from our users:
“Can I actually see how the browser runs my tasks?”
“I want to quickly test scripts without deploying them every time.”
That’s exactly why we built the Playground:
- ✅ Reusable and stable scraping/browser scripts
- ✅ A visual, interactive browser environment you can see, control, and replay
✨ Highlights of This Update
1. Brand-New Playground Interface
With this update, users can now directly use the Scraping Browser service within the Playground interface. The Playground is divided into two main sections:
- Code Panel (Left): Write and modify your automation scripts.
- Live Browser Preview (Right): Instantly view the browser actions as your script runs. It also supports manual clicks and interactions for real-time debugging.
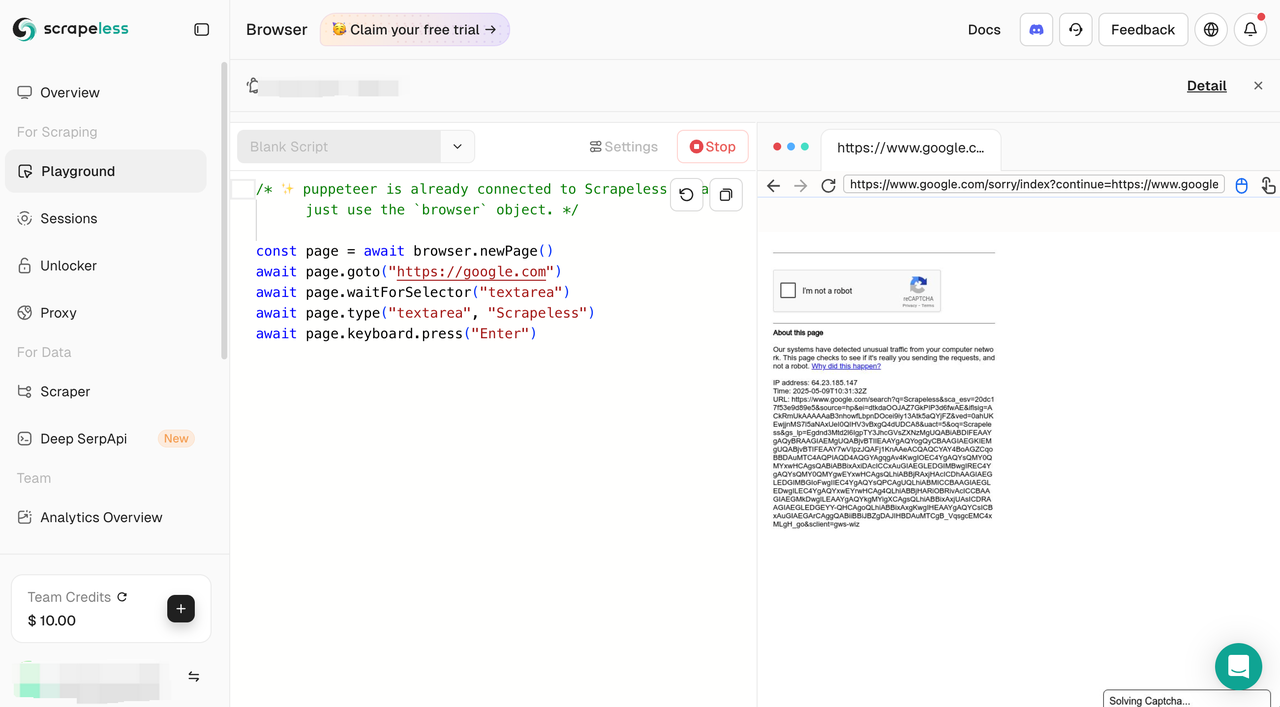
When no script is running, only the code panel is displayed. Once execution begins, the preview panel is activated—providing a seamless and efficient environment for development and debugging.
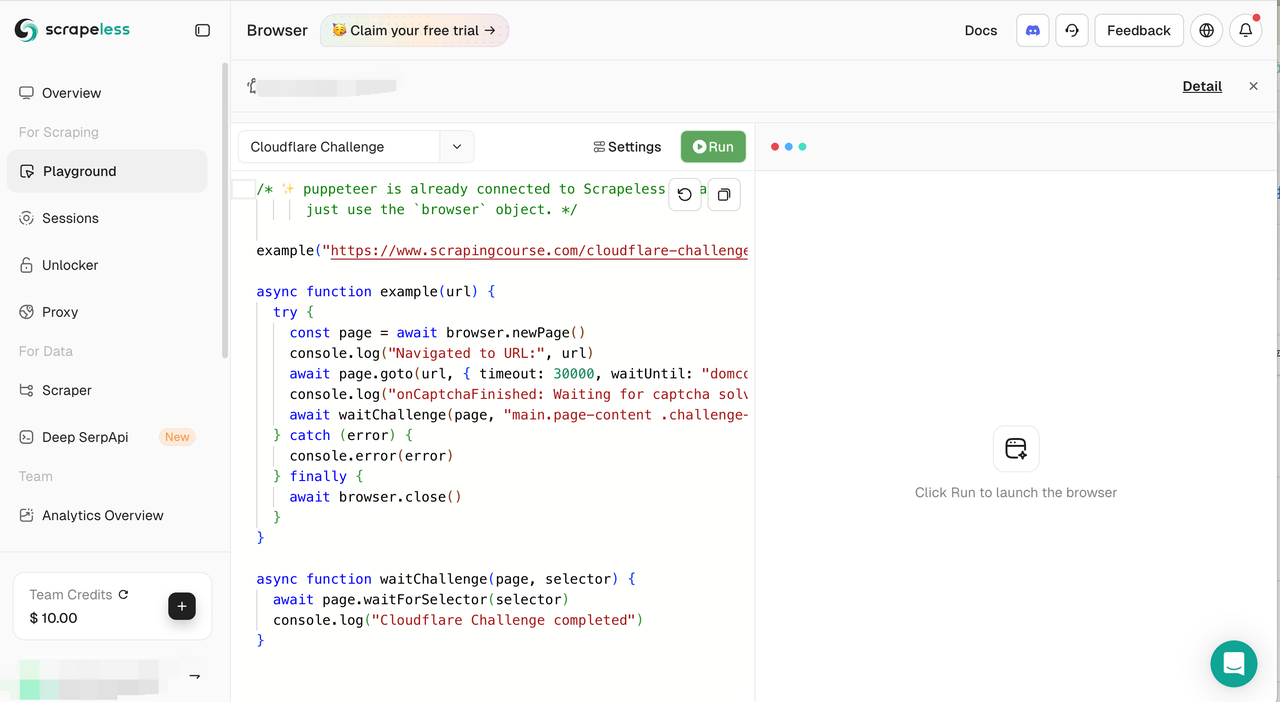
2. Case Selector for Common Scenarios
In the Playground, we’ve added a new Browser Cases feature to help you get started even faster. You can now:
- Quickly select a built-in use case from the dropdown menu (e.g., Generate PDF, Automatic Login, etc.).
- Automatically load example code for each case — ready for testing right away.
- Start from a Blank Script by default for full customization.
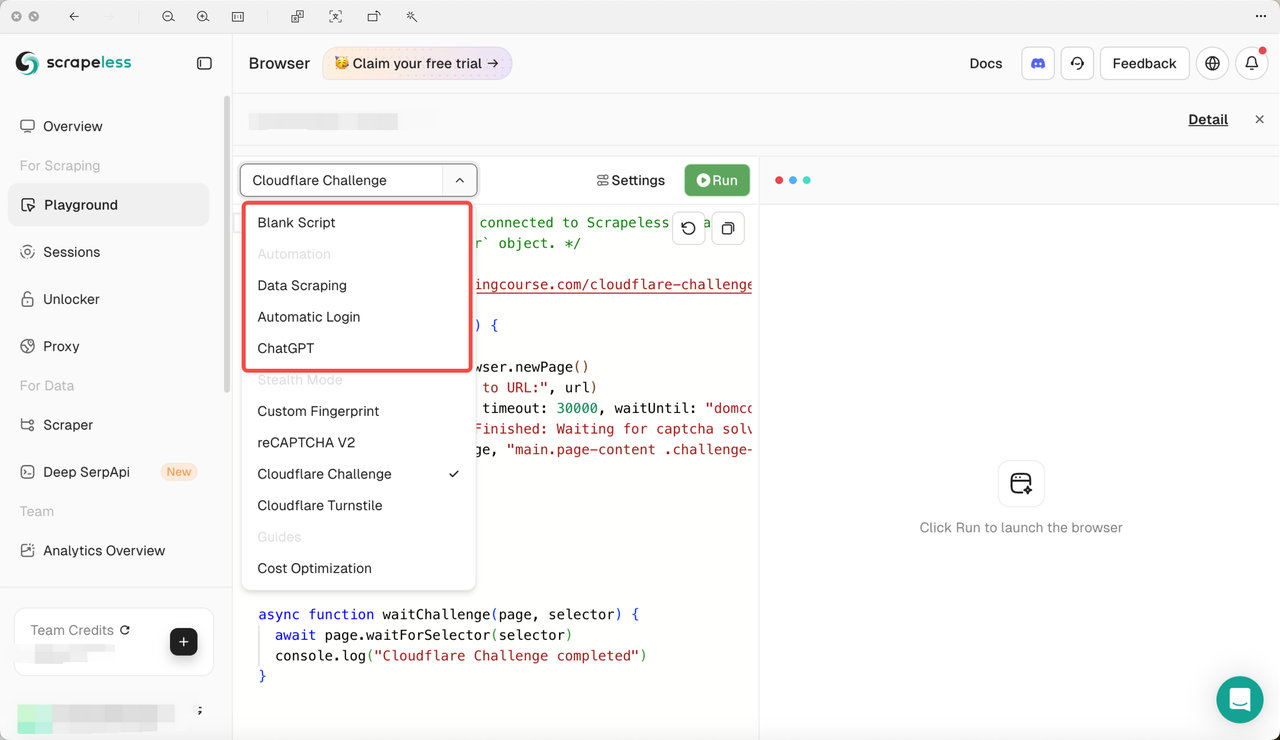
Scrapeless Scraping Browser currently supports a range of advanced features, including:
Custom Fingerprint, reCAPTCHA v2, Cloudflare Challenge, and Cloudflare Turnstile.
Currently supported cases in Playground include:
Data Scraping, Automatic Login, and ChatGPT Integration.
Example: Handling a Cloudflare Challenge
Let’s walk through an example using the Cloudflare Challenge case:
- Select Cloudflare Challenge from the dropdown. The left-side code editor will auto-fill with the relevant script. Click Run to execute it and view the real-time process in the right-side browser panel.
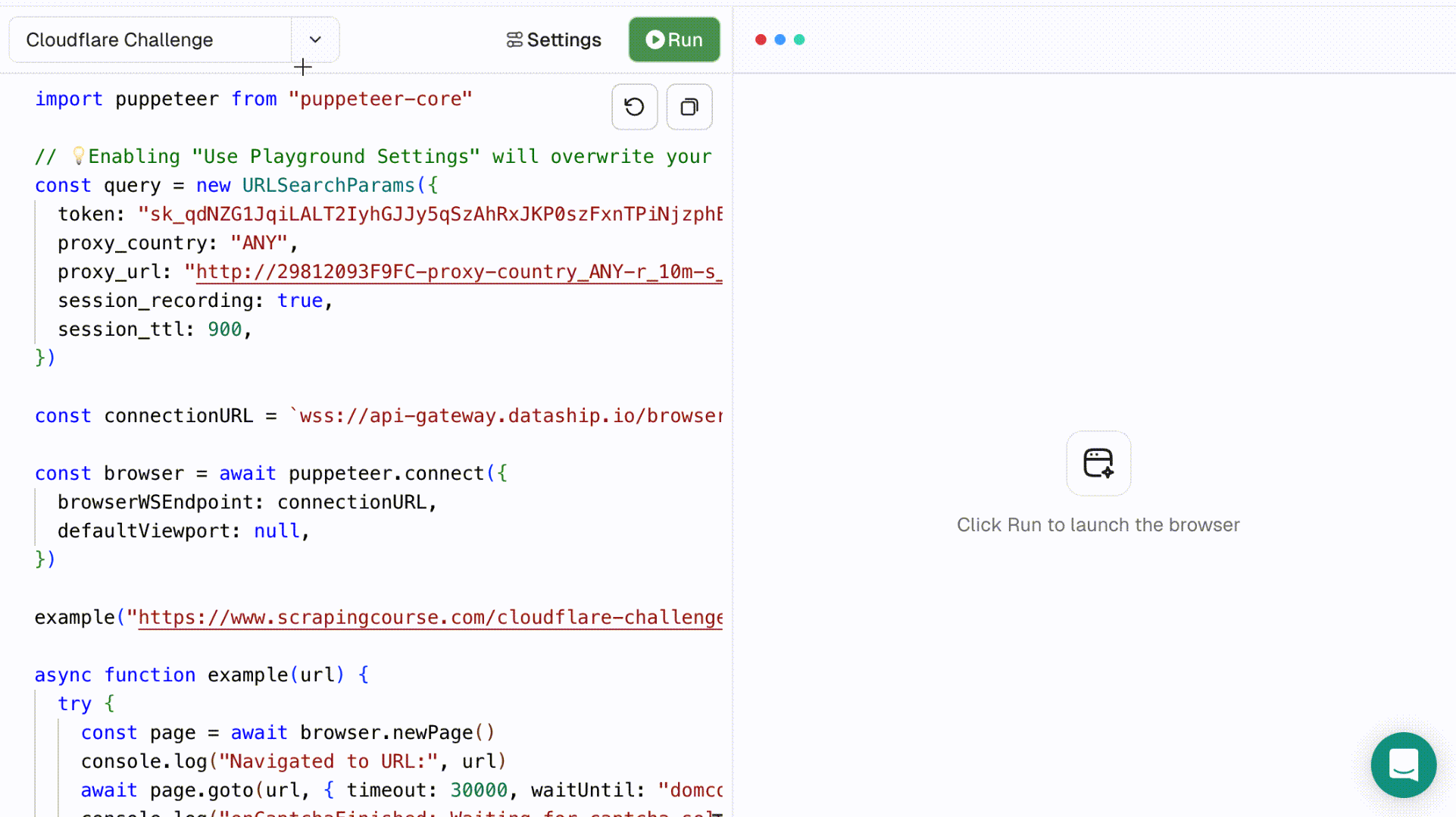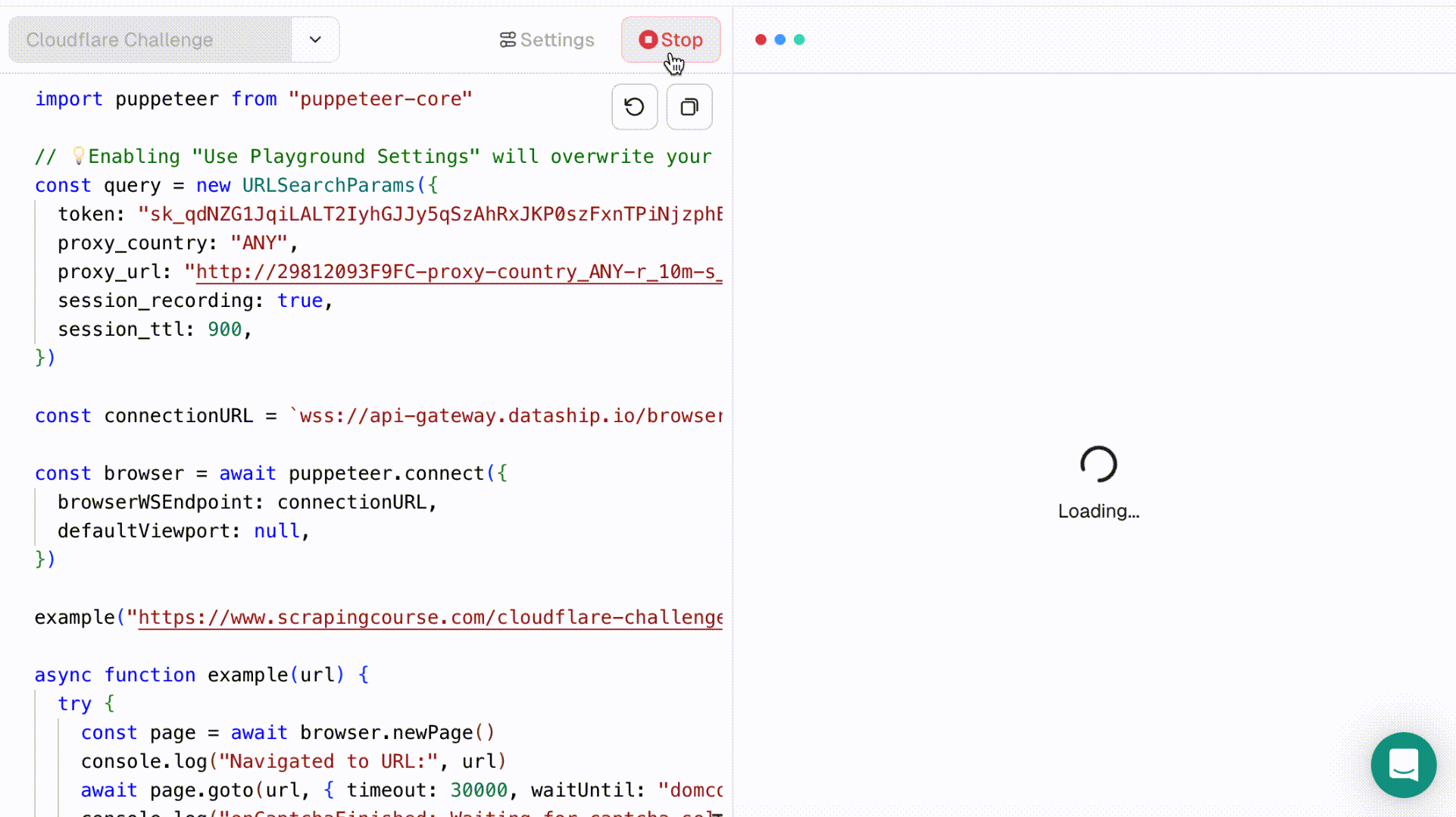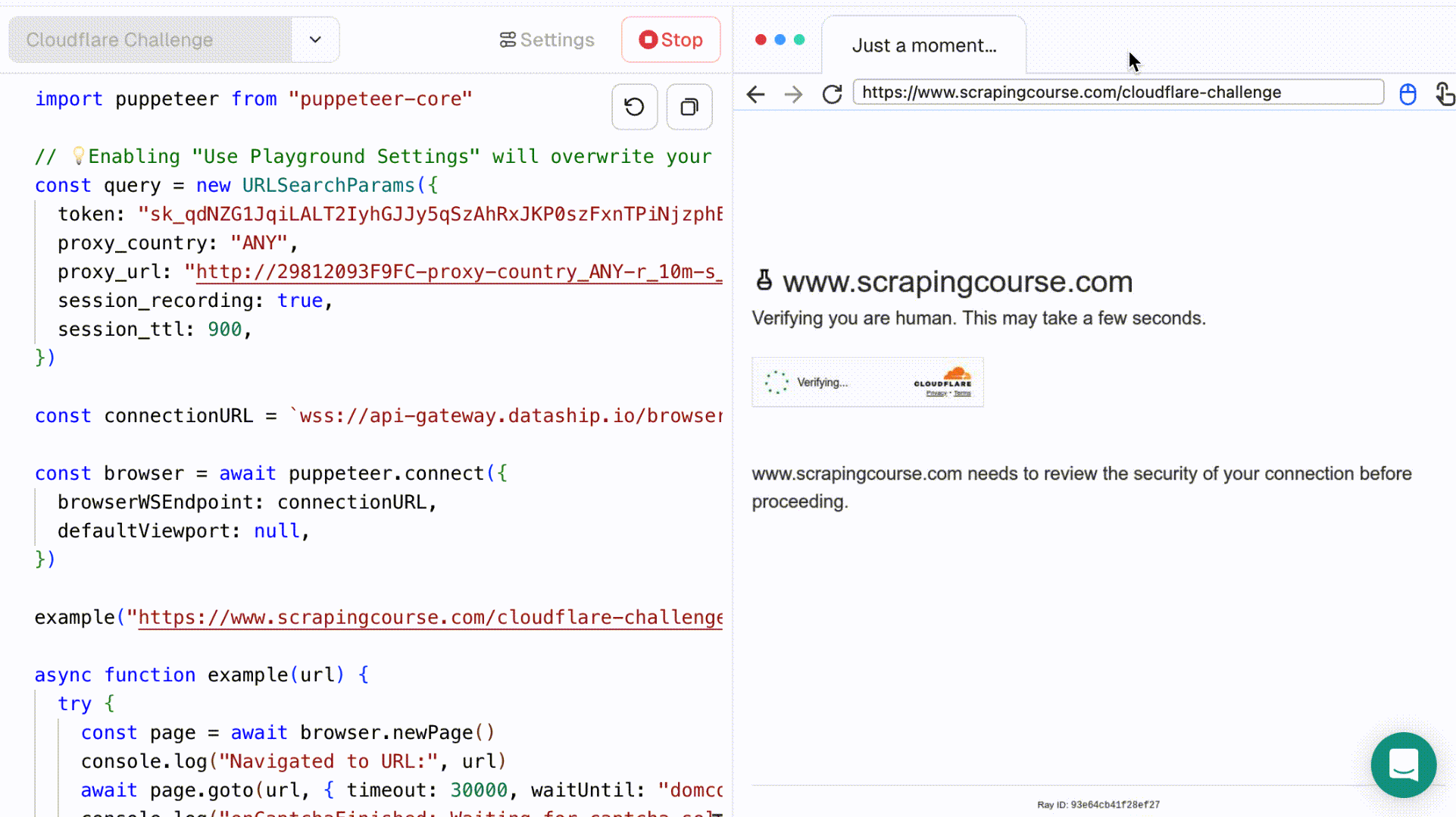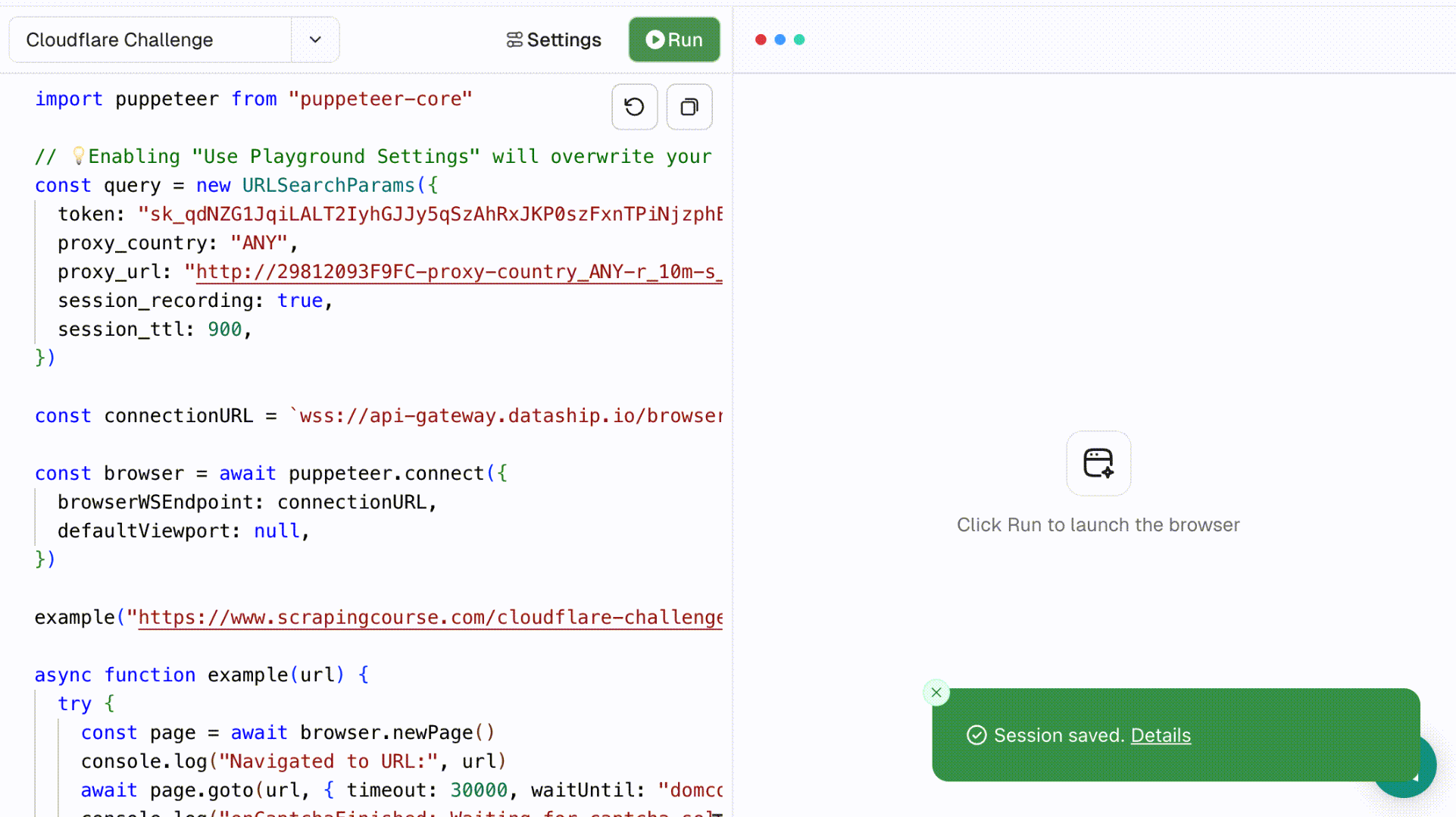
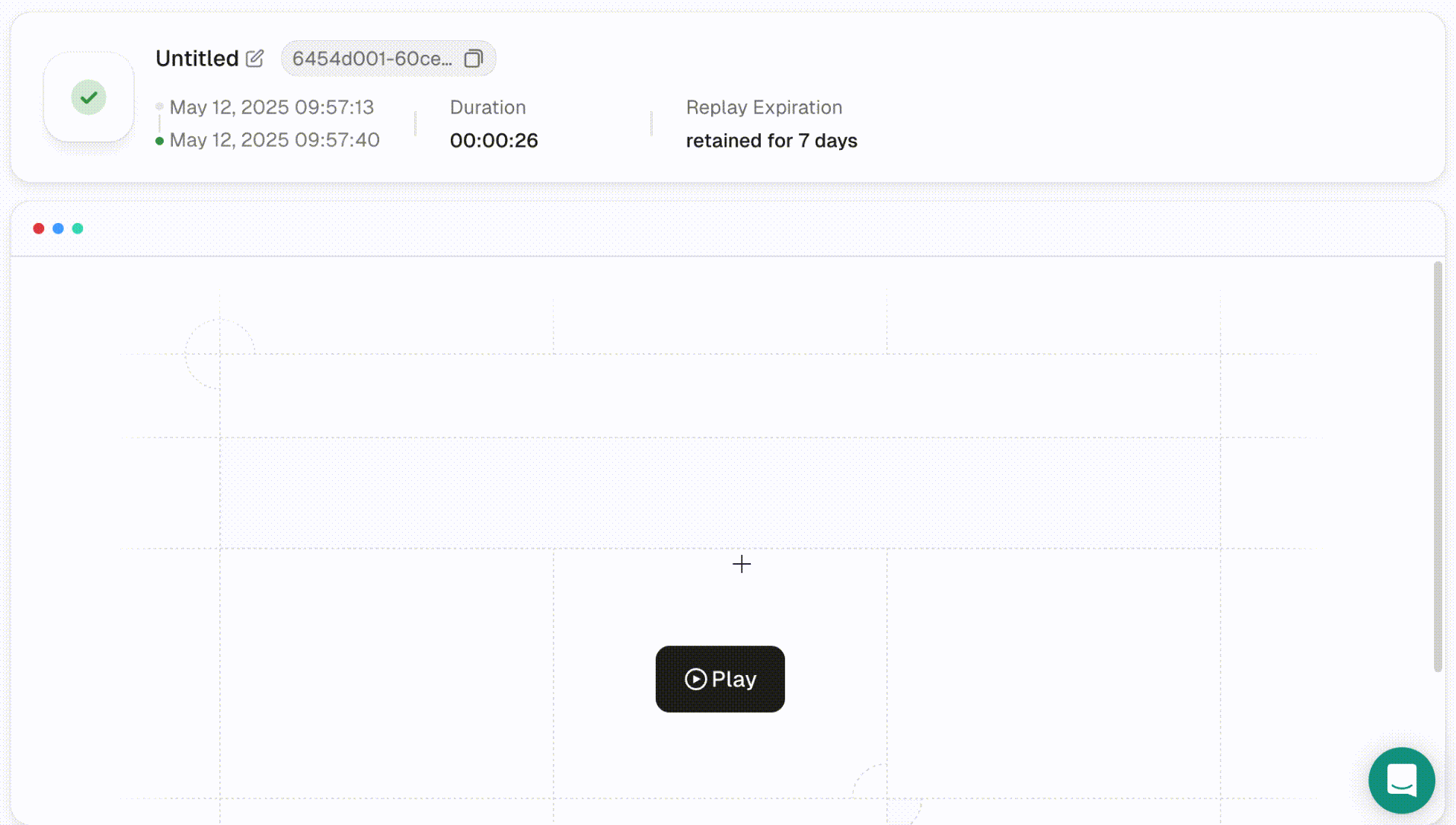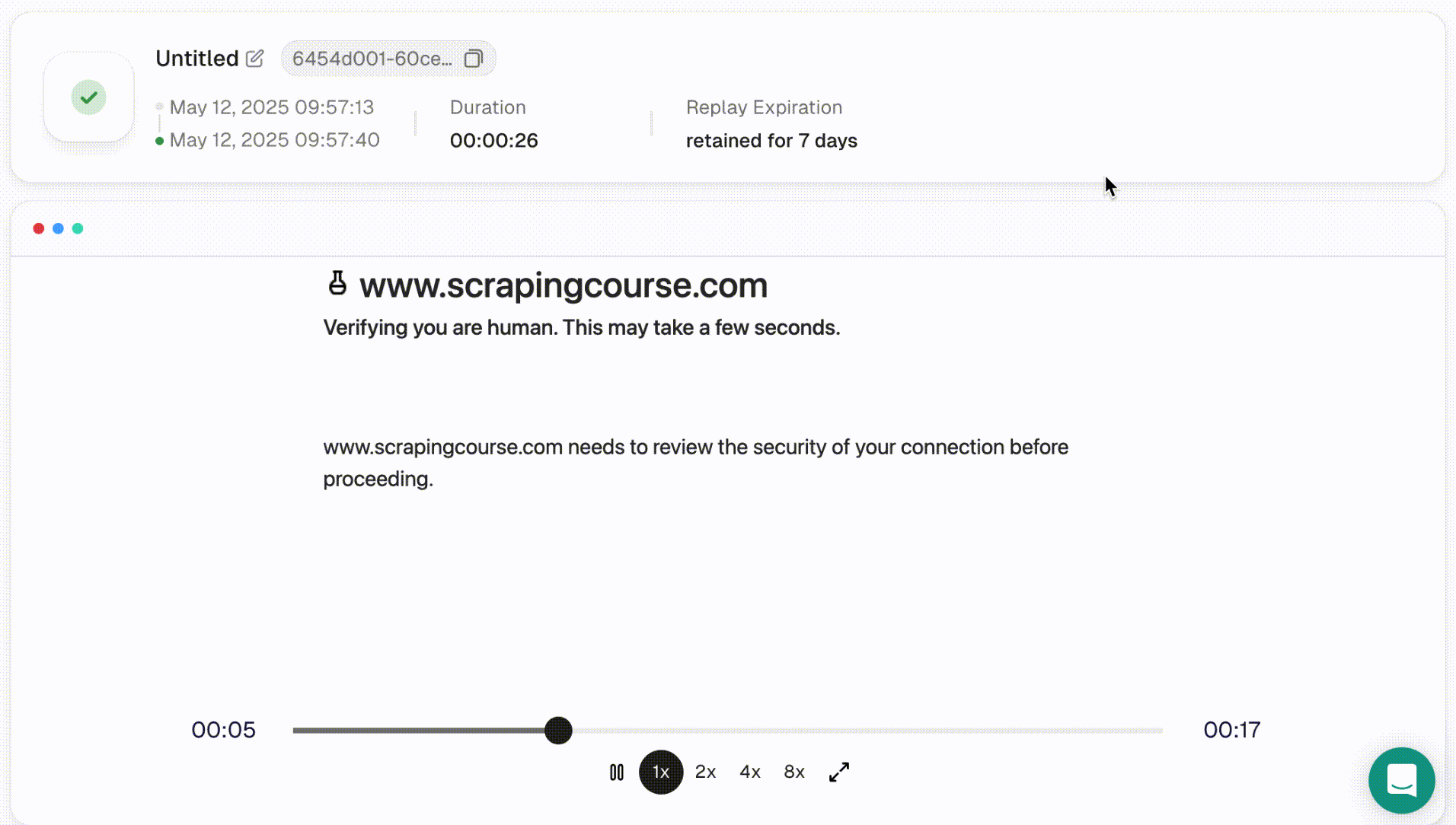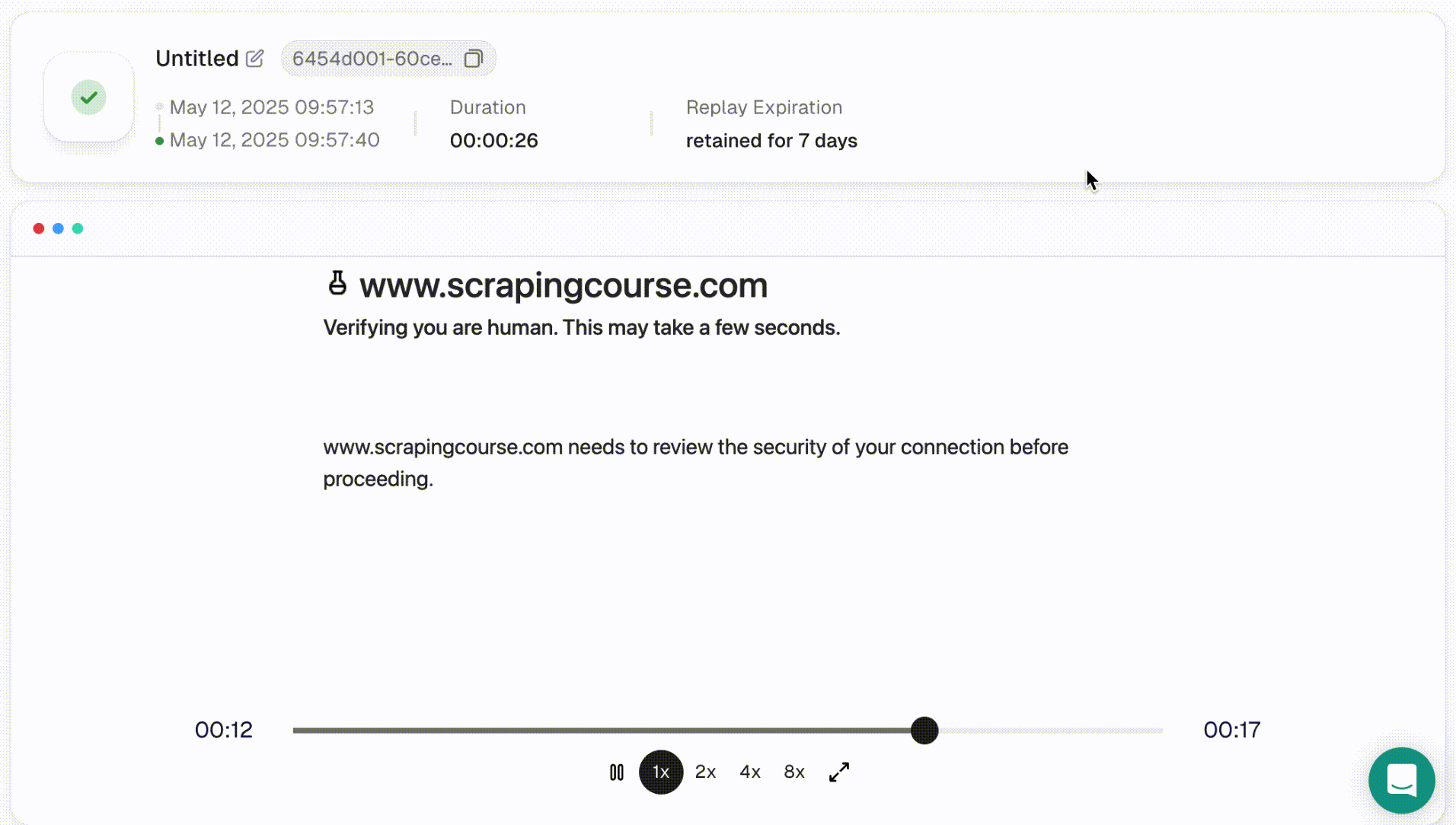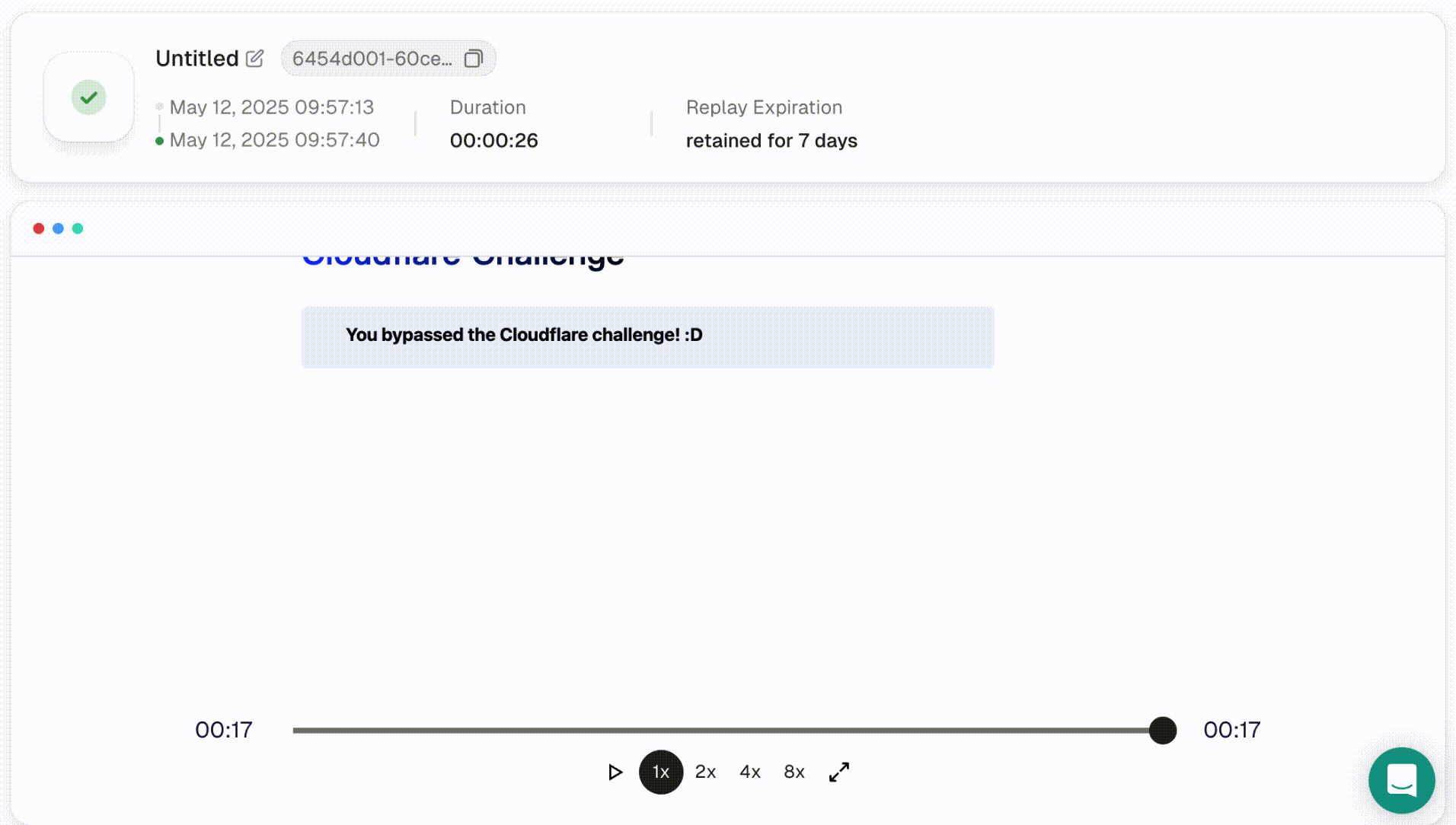
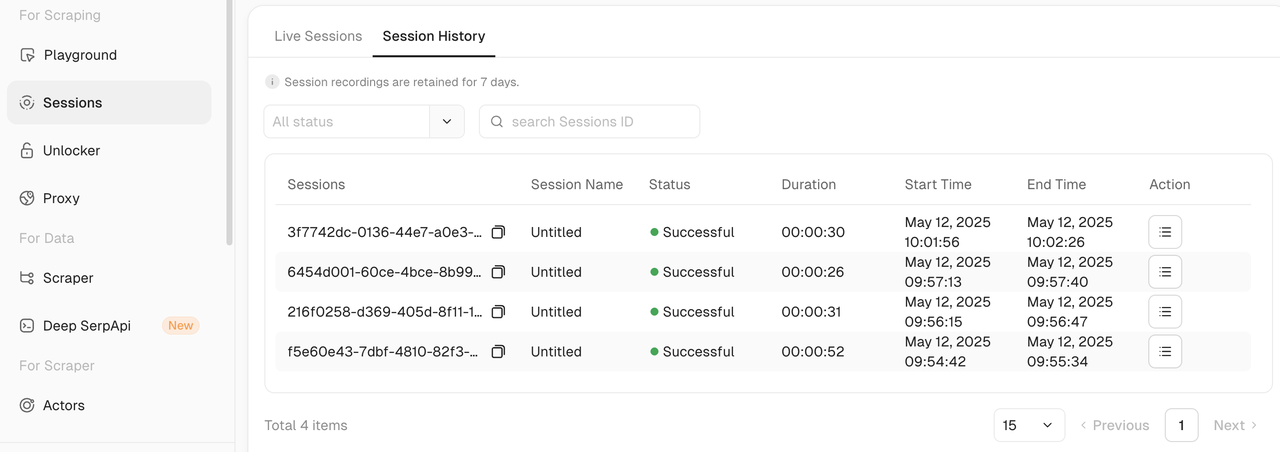
- Once the script finishes running, you can inspect the result in more detail using Session Replay. This feature supports adjustable playback speed and lets you review the full session.
Note: Each session and its replay data are stored for 15 days.
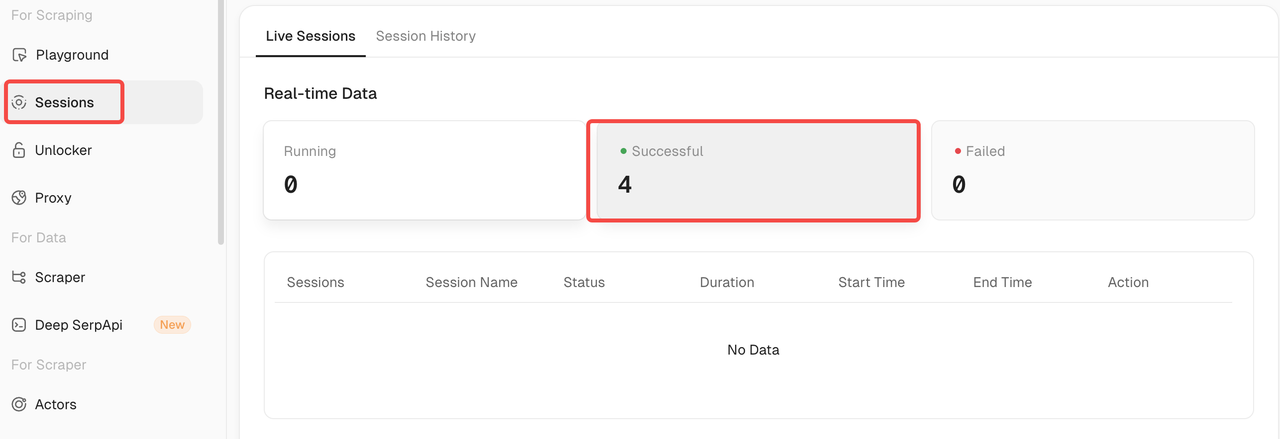
- You can also go to the Scrapeless dashboard, click on Session, and filter by Successful to view your full Session History.
3. Enhanced Settings Panel for Personalization
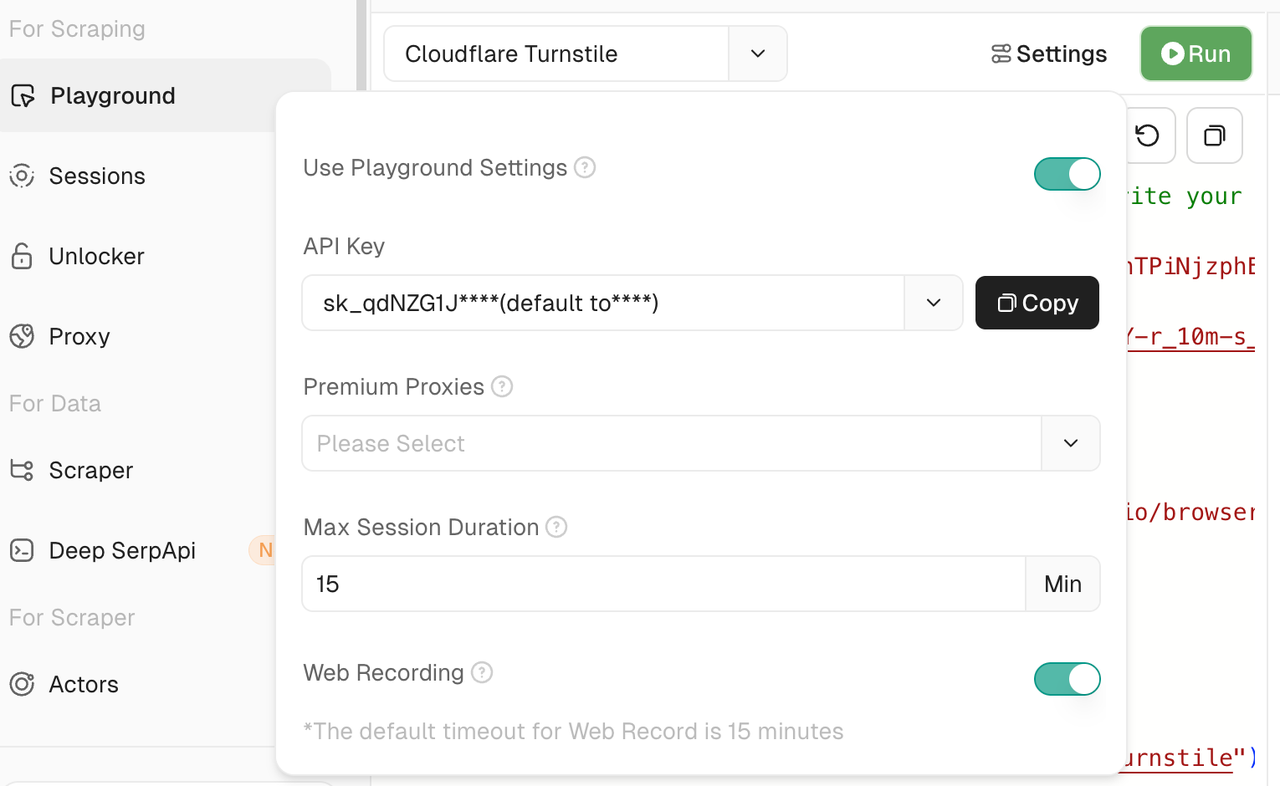
Click the Settings button to access a variety of customizable parameters that help tailor your experience in the Playground:
- API Key Display: See which API credential you’re currently using — clear and transparent.
- Proxy Selection: Switch between different proxy lines to better simulate real-world scraping environments.
- Max Timeout Setting: Define the maximum script execution time in minutes. The default is 15 minutes, but it can be extended indefinitely.
- Web Recording: Recording is enabled by default. All your browser interactions will be captured, allowing you to replay sessions later using Session Replay.
The session preview you see in the playground is scaled to the same size as the user’s screen.
Note:
To use Session Replay, you must enable Web Recording in the settings panel.
We highly recommend keeping it enabled by default to ensure all browser interactions are recorded properly.✅ No extra cost — Session Replay is included for free with your usage.
🔗 Click here to learn more about Session Replay
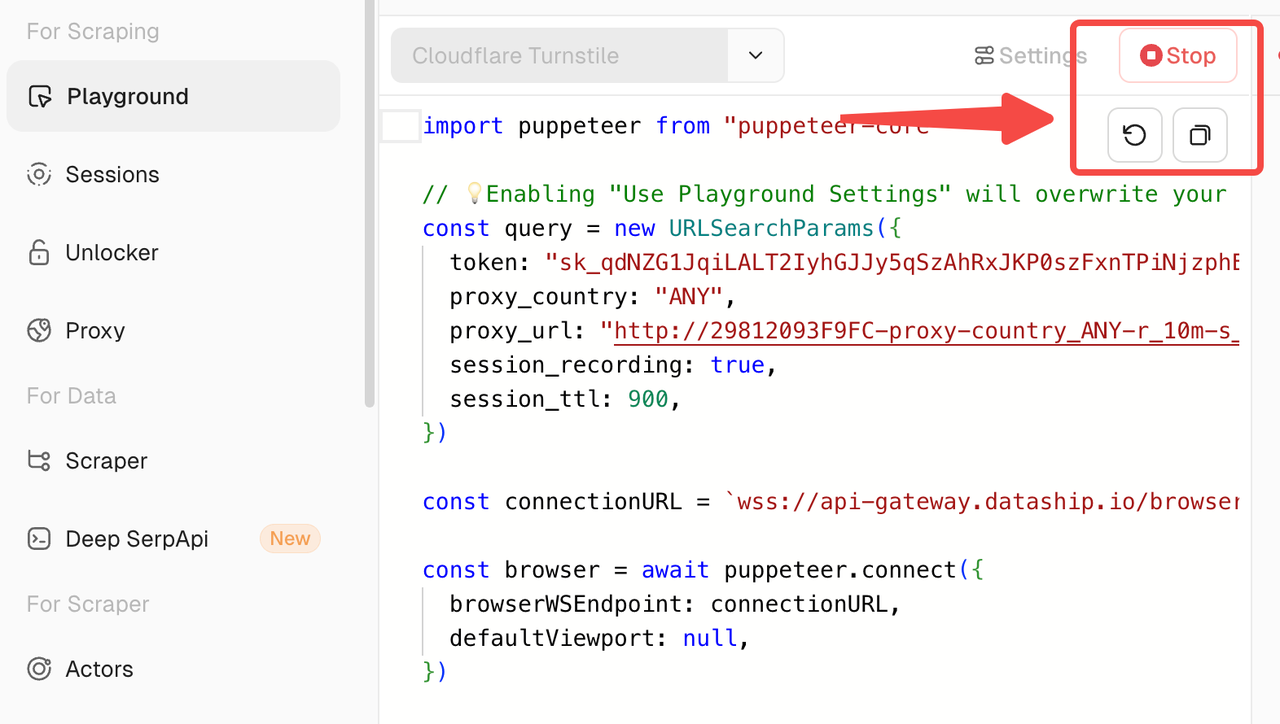
4. Developer-Friendly Utility Buttons
We’ve also added some helpful utility buttons to improve your development experience:
- Reset: Instantly reset the current script to the default template — perfect for quick rollbacks.
- Copy: Copy the current script content with a single click. A toast will confirm: “Code copied successfully”.
- Stop: Manually terminate a running session to avoid hanging or wasting resources.
Behind the Technology: What Powers Scrapeless Playground?
The Scrapeless team has built a robust, high-performance cloud browser infrastructure to enable this visual debugging experience. Designed for stability, scalability, and high concurrency, our platform combines headless browser technology with event-level monitoring to precisely simulate complex web behaviors — ensuring accurate, efficient debugging for all users.
Key Technical Highlights of Scrapeless Scraping Browser
-
Highly Realistic Browser Environment
- Dynamic Stealth Mode: Customize fingerprint parameters like User-Agent, device info, locale, OS, screen size, and language to mimic real user behavior. Integrated CAPTCHA solving and SDK support (Node.js, Python). Advanced stealth with Scrapeless Chromium.
- Headless & Headful Modes: Supports both browser modes to adapt to diverse anti-bot strategies.
-
Global Proxy & IP Management
- 70M+ Residential IPs across 195 countries with auto-rotating and geo-targeted routing.
- Transparent Pricing: Only $1.26–$1.80/GB vs. $9.5+/GB from other providers. You can also use your own proxy.
-
Automatic CAPTCHA Solving
- Built-in Solutions for reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, and more.
-
Session Replay
- Session Inspector: Monitor sessions in real-time for debugging.
- Live View: Interactively debug errors, analyze user behavior, and inspect proxy traffic for optimization.
- Session Recordings: Replay session steps to analyze operations and network activity comprehensively.
-
Multi-Type Scraping Methods
- Scrape: Extract data from a single page.
- Crawl: Full-site extraction with depth control and sitemap crawling.
- Extract: Prompt-based content extraction from a given page.
Learn more about Scrapeless Scraping Browser:
Future Plans
Playground is just one step in Scrapeless’s journey to enhance browser automation quality and productization. Moving forward, the Scrapeless team plans to iterate and upgrade across multiple areas:
1. Productization of Scraping Capabilities
- Standardize and productize the three major scraping capabilities: Scrape, Crawl, and Extract to support multi-modal data extraction (text, PDF, documents, images, etc.).
- Upgrade Scraping Browser features, including:
- Proxy usage tracking
- Custom permission configuration
- Optimized session replay for file-type sessions
2. Developer Ecosystem Expansion
- Launch a Developer Revenue Sharing Program to incentivize community contributions such as plugins and use-case templates.
3. Infrastructure Strengthening
Scrapeless will continue investing in its core scraping technology stack while enhancing product standardization and developer experience. Our long-term goal is to build an open, scalable, and developer-friendly automation platform.
💡 We Welcome Your Feedback!
Feel free to join our Discord community to share your experience or suggest new features.
👉 Try the new Playground and unlock more browser automation possibilities!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


