
Scrapeless SDK Officially Launched: Your All-in-One Solution for Web Scraping and Browser
Expert Network Defense Engineer
We’re thrilled to announce that the official Scrapeless SDK is now live! 🎉
It’s the ultimate bridge between you and the powerful Scrapeless platform — making web data extraction and browser automation simpler than ever.
With just a few lines of code, you can perform large-scale web scraping and SERP data extraction, providing stable support for Agentic AI systems.
The Scrapeless SDK offers developers an official wrapper for all core services, including:
- Scraping Browser: A Puppeteer & Playwright-based automation layer, supporting real clicks, form filling, and other advanced features.
- Browser API: Create and manage browser sessions, ideal for advanced automation needs.
- Scraping API: Fetch webpages and extract content in multiple formats.
- Deep SERP API: Easily scrape search engine results from Google and more.
- Universal Scraping API: General-purpose web scraping with JS rendering, screenshot, and metadata extraction.
- Proxy API: Instantly configure proxies, including IP addresses and geolocation.
Whether you're a data engineer, crawler developer, or part of a startup building data-driven products, the Scrapeless SDK helps you acquire the data you need faster and more reliably.
From browser automation to search engine result parsing, from web data extraction to automatic proxy management, the Scrapeless SDK streamlines your entire data acquisition workflow.
Scrapeless SDK Using Reference
Prerequisite
Log in to the Scrapeless Dashboard and get the API Key
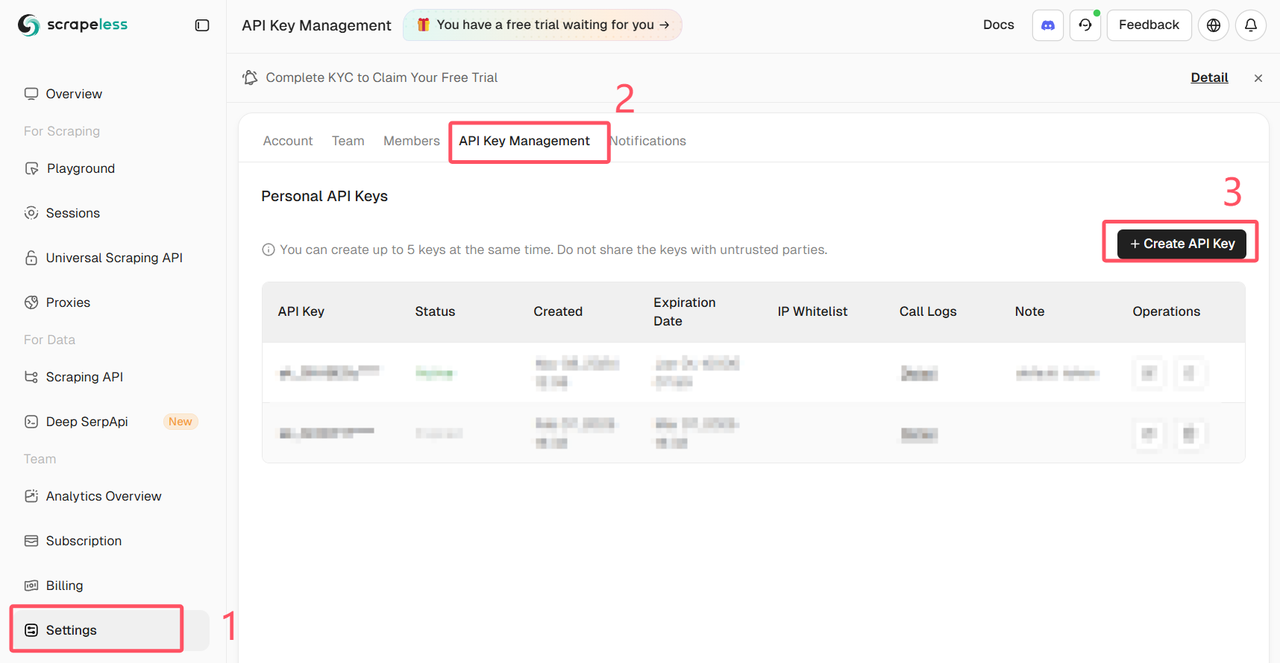
Installation
- npm:
Bash
npm install @scrapeless-ai/sdk- yarn:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdkBasic Setup
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// Initialize the client
const client = new Scrapeless({
apiKey: 'your-api-key' // Get your API key from https://scrapeless.com
});Environment Variables
You can also configure the SDK using environment variables:
Bash
# Required
SCRAPELESS_API_KEY=your-api-key
# Optional - Custom API endpoints
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.comScraping Browser (Browser Automation Wrapper)
The Scraping Browser module provides a high-level, unified API for browser automation, built on top of the Scrapeless Browser API. It supports both Puppeteer and Playwright, and extends the standard page object with advanced methods such as realClick, realFill, and liveURL for more human-like automation.
Puppeteer Example:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('Current page URL:', urlInfo.liveURL);
await browser.close();Playwright Example:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('Current page URL:', urlInfo.liveURL);
await browser.close();👉 Visit our documentation for more use cases
👉 One-click integration via GitHub
Hands-On Example: Scraping “Air Max” Search Results on Nike.com
Suppose you're building a backend system for a shoe comparison platform and need to fetch search results for “Air Max” from Nike's official site in real time. Traditionally, you’d have to deploy Puppeteer, handle proxies, evade blocks, parse page structures… time-consuming and error-prone.
Now, with Scrapeless SDK, the entire process takes just a few lines of code:
Step 1. Install SDK
Use your preferred package manager:
Python
npm install @scrapeless-ai/sdkStep 2. Initialize Client
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'your-api-key' // 在 https://scrapeless.com 获取
});Step 3. One-Click SERP Scraping
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);You don't need to worry about proxies, anti-bot mechanisms, browser emulation, or IP rotation — Scrapeless handles all of that under the hood.
Example Output
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=en-US',
source: 'Nike',
source_logo: '',
title: "Nike Air Max 1 Men's Shoes",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}You can now store these results in your database or use them directly for display and ranking analysis.
Install Scrapeless SDK Now
The Scrapeless Node.js SDK makes web scraping and browser automation easier than ever. Whether you're building a price monitoring tool, a SERP analysis system, or simulating real user behavior — a single line of code connects you to Scrapeless's powerful infrastructure.
The Scrapeless SDK is open-source under the MIT license. Developers are welcome to contribute code, submit issues, or join our Discord community for more ideas!
✅ Free Trial Available
🔗 Read the Docs
💬 Got Questions? Join Our Discord Community
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


